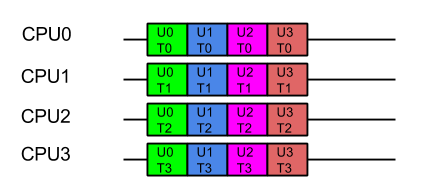
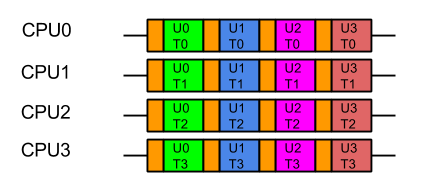
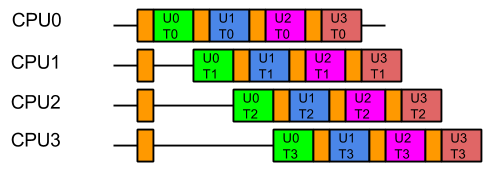
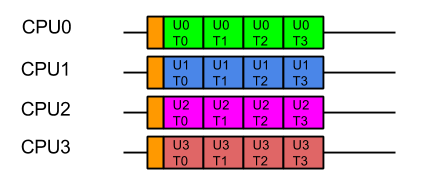
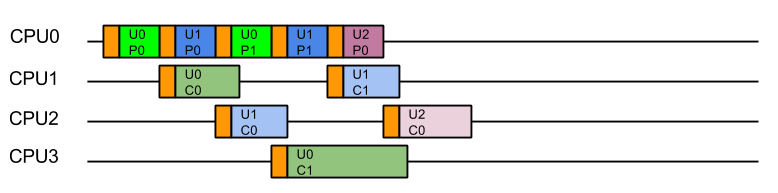
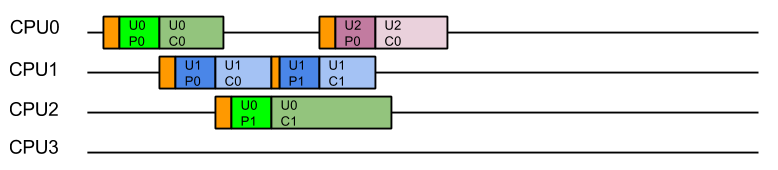
Java’s Virtual Threads (aka Project Loom or JEP 444) have arrived as a full platform feature in Java 21, which has generated considerable interest and many projects (including Eclipse Jetty) are adding support.
I have previously been somewhat skeptical about how significant any advantages Virtual Threads actually have over Platform Threads (aka Native Threads). I’ve also pointed out that cheap Threads can do expensive things, so that using Virtual Threads may not be a universal panacea for concurrent programming.
However, even with those doubts, it is clear that Virtual Threads do have advantages in memory utilization and speed of startup. In this blog we look at what kinds of applications may benefit from those advantages.
In short we investigate what scalability problems are Virtual Threads the solution for.
Axioms
Firstly let’s agree on what is accepted about Virtual Thread usage:
- Writing asynchronous code is extraordinary difficult. “Yeah I know” you say… yeah but no, it is harder than that! Avoiding the need to write application logic in asynchronous style is key to improving the quality and stability of an application. This blog is not generally advocating you write your applications in an asynchronous style.
- Virtual Threads are very cheap to create. From a performance perspective there is no reason to pool already started Virtual Threads and such pools are considered an anti pattern. If a Virtual Thread is needed, then just create a new one.
- Virtual Threads use less memory. This is accepted, but with some significant caveats. Specifically the memory saving is achieved because Virtual Threads only allocate stack memory as needed, whilst Platform Threads provision stack size based on a worst case maximal usage. This is not exactly an apples vs oranges comparison.
If some are good, are more even better?
Consider a blocking style application is running on a traditional application server that is not scaling sufficiently. On inspection you see that all the Threads in the pool (default size 200) are allocated and that there are no Threads available to do more work!
Would making more Threads available be the solution to this scalability problem? Perhaps 2000 Platform Threads will help? Still slow? Let’s try 10,000 Platform Threads! Running out of memory? Then perhaps unlimited Virtual Threads will solve the scalability problems?
What if on further inspection it is found that the pool Threads are mostly blocked waiting for a JDBC Database connection from the JDBC Connection Pool (default size 8) and that as a result the Thread pool is exhausted.
If every request needs the database, then any additional Threads will all just block on the same JDBC pool, thus more Threads will not make a more Scalable solution.
Alternatively, if only some requests need to use the database, then having more Threads would allow request that do not need the database to proceed to completion. However, a fraction of requests would still end up blocked on the JBDC pool. Thus any limited Platform Thread pool could still become exhausted.
With unlimited Virtual Threads there is no effective limit on the number of Threads, so non database requests could always continue, but the queue of Threads waiting on JBDC would also be unlimited as would the total of any resources held by those Threads whilst waiting. Thus the application would only scale for some types of request, whilst giving JDBC dependent requests the same poor Quality of Service as before.
Finite Resources
If an application’s scalability is constrained by access to a finite resource, then it is unlikely that “more Threads” is the solution to any scalability problems. Just like you can’t solve traffic by adding cars to a congested road, adding Threads to an already busy server may make things worse.
Some common examples of finite resources that applications can encounter are:
- CPU: If the server CPU is near 100% utilization, then the existing number of Threads are sufficient to keep it fully loaded. More and/or faster CPUs are needed before any increase in Threads could be beneficial.
- Database: Many database technologies cannot handle many concurrent requests, so parallelism is restricted. If the bottleneck is the database, then it needs to be re-engineered rather than laid siege to by more concurrent Threads.
- Local Network: An application may block reading or writing data because it has reached the limit on the local network. In such cases, more Threads will not increase throughput, but they might improve latency if some threads can progress reading new requests and have responses ready to write once network becomes less congested. However there is a cost in waiting (see below).
- Locks: Parallel applications often use some form of lock or mutual exclusion to serialize access to common data structures. Contention on those locks can limit parallelism and require redesign rather than just more Threads.
- Caches: CPU, memory, file system and object caches are key tools in speeding up execution. However, if too many different tasks are executed concurrently, the capacity of these caches to hold relevant data may be exceeded and execution with a cold cache can be very slow. Sometimes it is better to do less things concurrently and serialize the excess so that caches can be more effective that trying to do everything at once.
If an application’s lack of scalability is due to Threads waiting for finite resources, then any additional Threads (Platform or Virtual) are unlikely to help and may make your application less stable. At best, careful redesign is needed before Thread counts can be increased in any advantageous way.
Infinite (OK Scalable) Resources
Not all resources are finite and some can be considered infinite, at least for some purposes. But let’s call them “Scalable” rather than infinite. Examples of scalable resources that an application may block on include:
- Database: Not all databases are created equal and some types of database have scalability in excess of the request rates experienced by a server. However, such scalability often comes at a latency cost as the database may be remote and/or distributed, thus applications may block waiting for the database, even if it has capacity to handle more requests in parallel.
- Micro services: A scalable database is really just a specific example of a micro service that may be provided by a remote and/or distributed system that has effectively infinite capacity at the cost of some latency. Applications can often find themselves waiting on one or more such services.
- Remote Networks: Local data center networks are often very VERY fast and in many situations they can outstrip even the combined capacity of many client systems. An application sending/receiving larger content may may block writing/reading them due to a slow client, but still have enough local network capacity to communicate with many other clients in parallel.
- Local Filesystems: Typically file systems are faster than networks, but slower than CPU. They also may have significant latency vs throughput tradeoffs (less so now that drives seldom need to spin physical disks). Thus Threads may block on local IO even though there is additional capacity available.
Applications that lack scalability due to Threads waiting for such scalable resources may benefit from more Threads. Whilst some Threads are waiting for the a database, micro service, slow client network or file system, it is likely that other Threads can progress even if they need to access the same types of resources.
Platform Threads pools can easily be increased to many 1000’s or more before typical servers will have memory issues. If scalability is needed beyond that, then Virtual Threads can offer practically unlimited additional Thread, but see the caveats below.
Furthermore, the fast starting Virtual Threads can be of significant benefit in situations where small jobs with long latency can be carried out in parallel. Consider an application that processes request using data from several micro services, each with some access latency. If these are done serially, then the total request latency is the summation of all. Sometimes asynchronous code is used to execute micro service request in parallel, but spinning up a couple of Virtual Threads in this situation is simpler, less error prone and applicable to more APIs.
Too Much of a Good Thing?
There is also some concern with low latency scalable resources that seldom block with Virtual Threads. Since Virtual Threads are not preempted, there can be starvation and/or fairness problems if they are not blocked by slow resources. This is probably a good problem to have, but will need some management on extreme scales for some applications.
The Cost of Waiting
We have identified that there are indeed scalable resources on which an application may wait with many Threads. However, there is no such thing as a free lunch and waiting Threads may have a significant cost, even if they are Virtual. Specifically how/where an application waits can greatly affect resource usage.
Consider a traditional application server with a limited Thread pool that is running near capacity, but with additional demand. While the 200 odd Threads are busy handling 200 concurrent request, there are additional request waiting to be handled. However, in an asynchronous server like Jetty, those additional requests can be cheaply parked and may be represented just be a single set bit in a selector or perhaps a tiny entry in a queue that holds only a reference to a connection that is ready to be read.
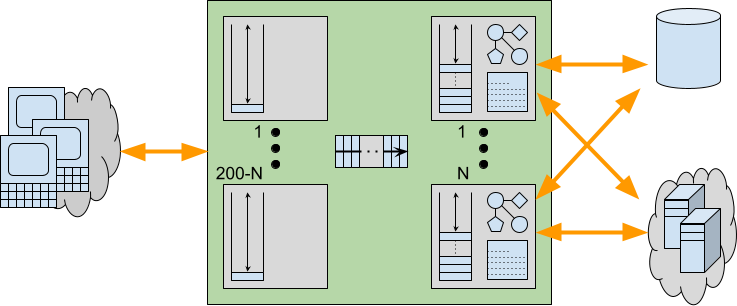
Now consider if requests were serviced by Virtual Threads instead of waiting for a pooled Platform Thread to become available. Pending requests would be allowed to proceed to some blocking point in the application. Waiting like this within the application can have additional expenses including:
- An input buffer will be allocated to read the request and any content it has.
- A read is performed into the input buffer, thus removing network back pressure so a client is enabled to send more request/data even if the server is unable to handle them.
- An object representation of the request will be built, containing at least the meta data and frequently some application data if there is an XML or JSON payload
- Sessions may be activated and brought into memory from caches or passivation stores.
- The allocated Thread runs deep inside the application code, potentially reaching near maximal stack depth.
- Application objects created on the heap are held in memory with references from the stack.
- An output buffer may be allocated, along with additional character conversion resources.
When request handling blocks within the application, all these additional resources may be allocated and held during that wait. Worse still, because of the lack of back pressure, a client may send more request/data resulting in more Threads and associated resources being allocated and also being held whilst the application waits for some resource.
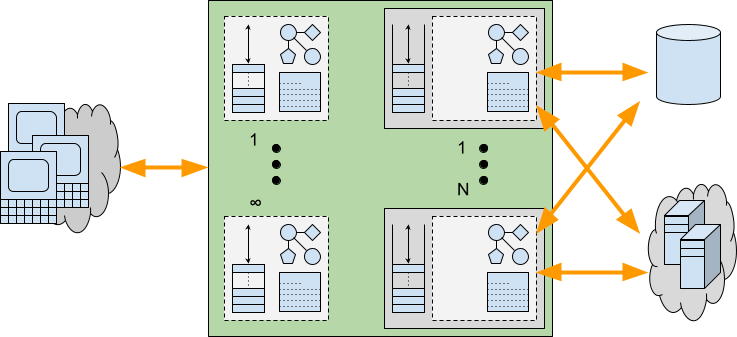
Provisioning for the Worst Case
We have seen that there are indeed applications that may benefit from having additional Threads available to service requests. But we have also seen that such additional Threads may incur additional costs beyond just the stack size. Waiting/Blocking within an application will typically be done with a deep stack and other resources allocated. Whilst Virtual Threads might be effectively infinite, it is unlikely that these other required resources are equally scalable.
When an application experiences a worst case peak in load, then ultimately some resource will run out. To provide good Quality of Service, it is vital that such resource exhaustion is handled gracefully, allowing some request handling to continue rather than suffering catastrophic failure.
With traditional Platform Thread based pools, stack memory is already provisioned for worst case stacks for all Threads and the thread pool sized limit is also an indirect limit on the number of concurrent resources used. Threads have sufficient resources available to complete there handling whilst any excess requests suffer latency whilst waiting cheaply for an available Thread. Furthermore, the back pressure resulting from not reading all offered requests can prevent additional load from sent by the clients. Thread limits are imperfect resource limits, but at least they are some kind of limit that can provide some graceful degradation under load.
Alternatively, an application using Virtual Threads that has no explicit resource management will be likely to exhaust some of the resources used by those Threads. This can result in an OutOfMemoryException or similar, as the unlimited Virtual Threads each allocate deep stacks and other resources needed for request handling. The cost of average memory savings may be insufficient provisioning for the worst case resulting in catastrophic failure rather than graceful degradation. An analogy is that building more roads can actually make traffic worse if the added cars overwhelm other infrastructure.
Many applications are written without explicit resource limitations/management. Instead they rely on the imperfect Thread pool for at least some minimal protection. If that is removed, then some form of explicit resource limitation/management is likely to be needed in its place. Stable servers need to be provisioned for the worst case, not the average one.
Conclusion
There are applications that can scale better if more Threads are available, but it is not all applications (at least not without significant redesign). Consideration needs to be given to what will limit the worst case load for a server/application if it is not to be Threads. Specifically, the costs of waiting within the application may be such that scalability is likely to have a limit that will not be enforced by practically infinite Virtual Threads.
It may be that resources have limitations well within the capacity of large but limited Platform Thread pools, which are perfectly capable of scaling to many thousands of threads. So experiments with scaling a Platform Thread pool should first be used to see what limits do apply to an application.
If no upper limit is found before Platform Threads exhaust kernel memory, then Virtual Threads will allow scaling beyond that limit until some other limit is found. Thus the ultimate resource limit will need to be explicitly managed if catastrophic failure is to be avoided (but, to be fair, applications using Thread pools should also do some explicit resource limit management rather than rely just on the course limits of a Thread pool).
Recommendation
If Virtual Threads are not the general solution to scalability then what is? There is no one-size-fits-all solution, but I believe many applications that are limited by blocking on the network would benefit from being deployed in a server like Eclipse Jetty, that can do much of the handling for them asynchronously. Let Jetty read your requests asynchronously and prepare the content as parsed JSON, XML, or form data. Only then allocate a Thread (Virtual or Platform) with a large output buffer so the application can be written in blocking style, but will not block on either reading the request or writing the response. Finally, once the response is prepared, then let Jetty flush it to the network asynchronously. Jetty has always somewhat supported this model (e.g. by delaying dispatch to a Servlet until the first packet of data arrives), but with Jetty-12 we are adding more mechanisms to asynchronously prepare requests and flush responses, whilst leaving the application written in blocking style. More to come on this in future blogs!