“Project Loom aims to drastically reduce the effort of writing, maintaining, and observing high-throughput concurrent applications that make the best use of available hardware. … The problem is that the thread, the software unit of concurrency, cannot match the scale of the application domain’s natural units of concurrency — a session, an HTTP request, or a single database operation. … Whereas the OS can support up to a few thousand active threads, the Java runtime can support millions of virtual threads. Every unit of concurrency in the application domain can be represented by its own thread, making programming concurrent applications easier. Forget about thread-pools, just spawn a new thread, one per task.” – Ron Pressler, State of Loom, May 2020
In this series of blogs, we are examining the new Loom virtual thread features now available in OpenJDK 16 early access releases. In part 1 we saw that Loom’s claim of 1,000,000 virtual threads was true, but perhaps a little misleading, as that only applies to threads with near-empty stacks. If threads actually have deep stacks, then the achieved number of virtual threads is bound by memory and is back to being the same order of magnitude as kernel threads. In this part, we will further examine the claims and ramifications of Project Loom, specifically if we can now forget about Thread Pools. Spoiler: Cheap threads can do expensive things!
All the code from this blog is available in our loom-trial project and has been run on my dev machine (Intel® Core™ i7-6820HK CPU @ 2.70GHz × 8, 32GB memory, Ubuntu 20.04.1 LTS 64-bit, OpenJDK Runtime Environment (build 16-loom+9-316)) with no specific tuning and default settings unless noted otherwise.
Matching the scale?
Project Loom makes the claim that applications need threads because kernel threads “cannot match the scale of the application domain’s natural units of concurrency”!
Really??? We’ve seen that without tuning, we can achieve 32k of either type of thread on my laptop. We think it would be fair to assume that with careful tuning, that could be stretched to beyond 100k for either technology. Is this really below the natural scale of most applications? How many applications have a natural scale of more than 32k simultaneous parallel tasks? Don’t get me wrong, there are many apps that do exceed those scales and Jetty has users that put an extra 0 on that, but they are the minority and in reality very few applications are ever going to see that demand for concurrency.
So if the vast majority of applications would be covered by blocking code with a concurrency of 32k, then what’s the big deal? Why do those apps need Loom? Or, by the same argument, why would they need to be written in asynchronous style?
The answer is that you rarely see any application deployed with 10,000s of threads; instead, threads are limited by a thread pool, typically to 100s or 1000s of threads. The default thread pool size in jetty is 200, which we sometimes see increased to 1000s, but we have never seen a 32k thread pool even though my un-tuned laptop could supposedly support it!
So what’s going on? Why are thread pools typically so limited and what about the claim that Loom means we can “Forget about thread pools”?
Why Thread Pools?
One reason we are told that thread pools are used is because kernel threads are slow to start, thus having a bunch of them pre-started, waiting for a task in a pool improves latency. Loom claims their virtual threads are much faster to start, so let’s test that with StartThreads, which reports:
kStart(ns) ave:137,903 from:1,000 min:47,466 max:6,048,540 vStart(ns) ave: 10,881 from:1,000 min: 4,648 max: 486,078
So that claim checks out. Virtual threads start an order of magnitude faster than kernel threads. If start time was the only reason for thread pools, then Loom’s claim of forgetting about thread pools would hold.
But start time only explains why we have thread pools, but it doesn’t explain why thread pools are frequently sized far below the systems capacity for threads: 100s instead of 10,000s? What is the reason that thread pools are sized as they are?
Why Small Thread Pools?
Giving a thread a task to do is a resource commitment. It is saying that a flow of control may proceed to consume CPU, memory and other resources that will be needed to run to completion or at least until a blocking point, where it can wait for those resources. Most of those resources are not on the stack, thus limiting the number of available threads is a way to limit a wide range of resource consumption and give quality of service:
- If your back-end services can only handle 100s of simultaneous requests, then a thread pool with 100s of threads will avoid swamping them with too much load. If your JDBC driver only has 100 pooled connections, then 1,000,000 threads hammering on those connections or other locks are going to have a lot of contention.
- For many applications a late response is a wrong response, thus it may well be better to handle 1000 tasks in a timely way with the 1001st task delayed, rather than to try to run all 1001 tasks together and have them all risk being late.
- Graceful degradation under excess load. Processing a task will need to use heap memory and if too much memory is demanded an OutOfMemeoryException is fatal for all java applications. Limiting the number of threads is a coarse grained way of limiting a class of heap usage. Indeed in part 1, we saw that it was heap memory that limited the number of virtual threads.
Having a limited thread pool allows an application to be tested to that limit so that it can be proved that an application has the memory and other resources necessary to service all of those threads. Traditional thinking has been that if the configured number of threads is insufficient for the load presented, then either the excess load must wait, or the application should start using asynchronous techniques to more efficiently use those threads (rather than increase the number of threads beyond the resource capacity of the machine).
A limited thread pool is a coarse grained limit on all resources, not only threads. Limiting the number of threads puts a limit on concurrent lock contention, memory consumption and CPU usage.
Virtual Threads vs Thread Pool
Having established that there might be some good reasons to use thread pools, let’s see if Loom gives us any good reasons not to use them? So we have created a FakeDataBase class which simulates a JDBC connection pool of 100 connections with a semaphore and then in ManyTasks we run 100,000 tasks that do 2 selects and 1 insert to the database, with a small amount of CPU consumed both with and without the semaphore acquired. The core of the thread pool test is:
for (int i = 0; i < tasks; i++) pool.execute(newTask(latch));
and this is compared against the Loom virtual thread code of:
for (int i = 0 ; i < tasks; i++) Thread.builder().virtual().task(newTask(latch)).start();
And the results are…. drum roll… pretty much the same for both types of thread:
Pooled K Threads 33,729ms Spawned V Threads 34,482ms
The pooled kernel thread does appear to be consistently a little bit better, but this test is not that rigorous so let’s call it the same, which is kind of expected as the total duration is pretty much going to be primarily constrained by the concurrency of the database.
So were there any difference at all? Here is the system monitor graph during both runs: kernel threads with a pool are the left hand first period (60-30s) and then virtual threads after a change over peak (30s – 0s):
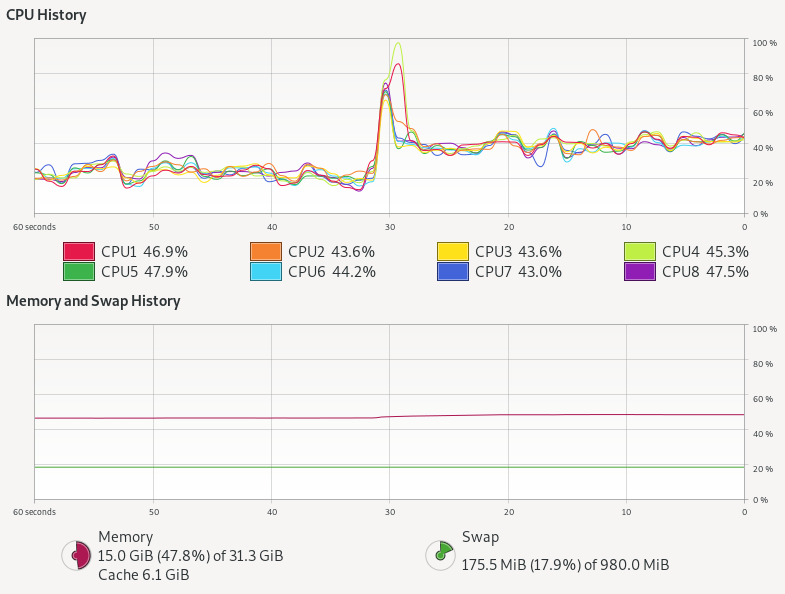
Kernel threads with thread pool do not stress the CPU at all, but virtual threads alone use almost twice as much CPU! There is also a hint of more memory being used.
The thread pool has 100k tasks in the thread pool queue, 100 kernel threads that take tasks, 100 at a time, and each task takes one of 100 semaphores permits 3 times, with little or no contention.
The Loom approach has 100k independent virtual threads that each contend 3 times for the 100 semaphore permits, with up to 99,900 threads needing to be added then removed 3 times from the semaphore’s wake up queue. The extra queuing for virtual threads could easily explain the excess CPU needed, but more investigation is needed to be definitive.
However, tasks limited by a resource like JDBC are not really the highly concurrent tasks that Loom is targeted at. To truly test Loom (and async), we need to look at a type of task that just won’t scale with blocking threads dispatched from a thread pool.
Virtual Threads vs Async APIs
One highly concurrent work load that we often see on Jetty is chat room style interaction (or games) written on CometD and/or WebSocket. Such applications often have many 10,000s or even 100,000s of connections to the server that are mostly idle, waiting for a message to receive or an event to send. Currently we achieve these scales only by asynchronous threadless waiting, with all its ramifications of complex async APIs into the application needing async callbacks. Luckily, CometD was originally written when there was only async servlets and not async IO, thus it still has the option to be deployed using blocking I/O reads and writes. This gives it good potential to be a like for like comparison between async pooled kernel threads vs blocking virtual threads.
However, we still have a concern that this style of application/load will not be suitable for Loom because each message to a chat room will fan out to the 10s, 100s or even 1000s of other users waiting in that room. Thus a single read could result in many blocking write operations, which are typically done with deep stacks (parsing, framework, handling, marshalling, then writing) and other resources (buffers, locks etc). You can see in the following flame graph from a CometD load test using Loom virtual threads, that even with a fast client the biggest block of time is spent in the blue peak on the left, that is writing with deep stacks. It is this part of the graph that needs to scale if we have either more and/or slower clients:

Jetty with CometD chat on Loom
To fairly test Loom, it is not sufficient to just replace the limited pool of kernel threads with infinite virtual threads. Jetty goes to lots of effort with its eat what you kill scheduling using reserved threads to ensure that whenever a selector thread calls a potentially blocking task, another selector thread has been executed. We can’t just put Loom virtual threads on top of this, else it will be paying the cost and complexity of core Jetty plus the overheads of Loom. Moreover, we have also learnt the risk of Thread Starvation that can result in highly concurrent applications if you defer important tasks (e.g. HTTP/2 flow control). Since virtual threads can be postponed (potentially indefinitely) by CPU bound applications or the use of non-Loom-aware locks (such as the synchronized keyword), they are not suitable for all tasks within Jetty.
Thus we think a better approach is to keep the core of Jetty running on kernel threads, but to spawn a virtual thread to do the actual work of reading, parsing, and calling the application and writing the response. If we flag those tasks with InvocationType.NON_BLOCKING, then they will be called directly by the selector thread, with no executor overhead. These tasks can then spawn a new virtual thread to proceed with the reading, parsing, handling, marshalling, writing and blocking. Thus we have created the jetty-10.0.x-loom branch, to use this approach and hopefully give a good basis for fair comparisons.
Our initial runs with our CometD benchmark with just 20 clients resulted in long GCs followed by out of memory failures! This is due to the usage of ThreadLocal for gathering latency statistics and each virtual thread was creating a latency capture data structure, only to use it once and then throw it away! While this problem is solvable by changing the CometD benchmark code, it reaffirms that threads use resources other than stack and that Loom virtual threads are not a drop in replacement for kernel threads.
We are aware that the handling of ThreadLocal is a well known problem in Loom, but until solved it may be a surprisingly hard problem to cope with, since you don’t typically know if a library your application depends on uses ThreadLocal or not.
With the CometD benchmark modified to not use ThreadLocal, we can now take Loom/Jetty/CometD to a moderate number of clients (1000 which generated the flame graph above) with the following results:
CLIENT: Async Jetty/CometD server
========================================
Testing 1000 clients in 100 rooms, 10 rooms/client
Sending 1000 batches of 10x50 bytes messages every 10000 µs
Elapsed = 10015 ms
- - - - - - - - - - - - - - - - - - - -
Outgoing: Rate = 990 messages/s - 99 batches/s - 12.014 MiB/s
Incoming: Rate = 99829 messages/s - 35833 batches/s(35.89%) - 26.352 MiB/s
@ _ 3,898 µs (112993, 11.30%)
@ _ 7,797 µs (141274, 14.13%)
@ _ 11,696 µs (136440, 13.65%)
@ _ 15,595 µs (139590, 13.96%) ^50%
@ _ 19,493 µs (142883, 14.29%)
@ _ 23,392 µs (130493, 13.05%)
@ _ 27,291 µs (112283, 11.23%) ^85%
@ _ 31,190 µs (59810, 5.98%) ^95%
@ _ 35,088 µs (12968, 1.30%)
@ _ 38,987 µs (4266, 0.43%) ^99%
@ _ 42,886 µs (2150, 0.22%)
@ _ 46,785 µs (1259, 0.13%)
@ _ 50,683 µs (910, 0.09%)
@ _ 54,582 µs (752, 0.08%)
@ _ 58,481 µs (567, 0.06%)
@ _ 62,380 µs (460, 0.05%) ^99.9%
@ _ 66,278 µs (365, 0.04%)
@ _ 70,177 µs (232, 0.02%)
@ _ 74,076 µs (82, 0.01%)
@ _ 77,975 µs (13, 0.00%)
@ _ 81,873 µs (2, 0.00%)
Messages - Latency: 999792 samples
Messages - min/avg/50th%/99th%/max = 209/15,095/14,778/35,815/78,184 µs
Messages - Network Latency Min/Ave/Max = 0/14/78 ms
SERVER: Async Jetty/CometD server
========================================
Operative System: Linux 5.8.0-33-generic amd64
JVM: Oracle Corporation OpenJDK 64-Bit Server VM 16-ea+25-1633 16-ea+25-1633
Processors: 12
System Memory: 89.26419% used of 31.164349 GiB
Used Heap Size: 73.283676 MiB
Max Heap Size: 2048.0 MiB
- - - - - - - - - - - - - - - - - - - -
Elapsed Time: 10568 ms
Time in Young GC: 5 ms (2 collections)
Time in Old GC: 0 ms (0 collections)
Garbage Generated in Eden Space: 3330.0 MiB
Garbage Generated in Survivor Space: 4.227936 MiB
Average CPU Load: 397.78314/1200
========================================
Jetty Thread Pool:
threads: 174
tasks: 302146
max concurrent threads: 34
max queue size: 152
queue latency avg/max: 0/11 ms
task time avg/max: 1/3316 ms
CLIENT: Loom Jetty/CometD server
========================================
Testing 1000 clients in 100 rooms, 10 rooms/client
Sending 1000 batches of 10x50 bytes messages every 10000 µs
Elapsed = 10009 ms
- - - - - - - - - - - - - - - - - - - -
Outgoing: Rate = 990 messages/s - 99 batches/s - 13.774 MiB/s
Incoming: Rate = 99832 messages/s - 41201 batches/s(41.27%) - 27.462 MiB/s
@ _ 2,718 µs (99690, 9.98%)
@ _ 5,436 µs (116281, 11.64%)
@ _ 8,155 µs (115202, 11.53%)
@ _ 10,873 µs (108572, 10.87%)
@ _ 13,591 µs (106951, 10.70%) ^50%
@ _ 16,310 µs (117139, 11.72%)
@ _ 19,028 µs (114531, 11.46%)
@ _ 21,746 µs (94080, 9.42%) ^85%
@ _ 24,465 µs (71479, 7.15%)
@ _ 27,183 µs (34358, 3.44%) ^95%
@ _ 29,901 µs (11526, 1.15%) ^99%
@ _ 32,620 µs (4513, 0.45%)
@ _ 35,338 µs (2123, 0.21%)
@ _ 38,056 µs (988, 0.10%)
@ _ 40,775 µs (562, 0.06%)
@ _ 43,493 µs (578, 0.06%) ^99.9%
@ _ 46,211 µs (435, 0.04%)
@ _ 48,930 µs (187, 0.02%)
@ _ 51,648 µs (31, 0.00%)
@ _ 54,366 µs (27, 0.00%)
@ _ 57,085 µs (1, 0.00%)
Messages - Latency: 999254 samples
Messages - min/avg/50th%/99th%/max = 192/12,630/12,476/29,704/54,558 µs
Messages - Network Latency Min/Ave/Max = 0/12/54 ms
SERVER: Loom Jetty/CometD server
========================================
Operative System: Linux 5.8.0-33-generic amd64
JVM: Oracle Corporation OpenJDK 64-Bit Server VM 16-loom+9-316 16-loom+9-316
Processors: 12
System Memory: 88.79622% used of 31.164349 GiB
Used Heap Size: 61.733116 MiB
Max Heap Size: 2048.0 MiB
- - - - - - - - - - - - - - - - - - - -
Elapsed Time: 10560 ms
Time in Young GC: 23 ms (8 collections)
Time in Old GC: 0 ms (0 collections)
Garbage Generated in Eden Space: 8068.0 MiB
Garbage Generated in Survivor Space: 3.6905975 MiB
Average CPU Load: 413.33084/1200
========================================
Jetty Thread Pool:
threads: 14
tasks: 0
max concurrent threads: 0
max queue size: 0
queue latency avg/max: 0/0 ms
task time avg/max: 0/0 ms
The results here are a bit mixed, but there are some positives for Loom:
- Both approaches easily achieved the 1000 msg/s sent to the server and 99.8k msg/s received from the server (messages have an average fan-out of a factor 100).
- The Loom version broke up those messages into 41k responses/s whilst the async version used bigger batches at 35k responses/s, which each response carrying more messages. We need to investigate why, but we think Loom is faster at starting to run the task (no time in the thread pool queue, no time to “wake up” an idle thread).
- Loom had better latency, both average (~12.5 ms vs ~14.8 ms) and max (~54.6 ms vs ~78.2 ms)
- Loom used more CPU: 413/1200 vs 398/1200 (4% more)
- Loom generated more garbage: ~8068.0 MiB vs ~3330.0 MiB and less objects made it to survivor space.
This is an interesting but inconclusive result. It is at a low scale on a fast loopback network with a client unlikely to cause blocking, so not really testing either approach. We now need to scale this test to many 10,000s of clients on a real network, which will require multiple load generation machines and careful measurement. This will be the subject of part 3 (probably some weeks away).
Conclusion (part 2) – Cheap threads can do expensive things
It is good that Project Loom adds inexpensive and fast spawning/blocking virtual threads to the JVM. But cheap threads can do expensive things!
Having 1,000,000 concurrent application entities is going to take memory, CPU and other resources, no matter if they block or use async callbacks. It may be that entirely different programming styles are needed for Loom, as is suggested by Loom Structured Concurrency, however we have not yet seen anything that provides limitations on resources that can be used by unlimited spawning of virtual threads. There are also indications that Loom’s flexible stack management comes with a CPU cost. However, it has been moderately simple to update Jetty to experiment with using Loom to call a blocking application and we’d very much encourage others to load test their application on the jetty-10.0.x-loom branch.
Many of Loom’s claims have stacked up: blocking code is much easier to write, virtual threads are very fast to start and cheap to block. However, other key claims either do not hold up or have yet to be substantiated: we do not think virtual threads give natural scaling as threads themselves are not the limiting factor, rather it is the resources that are used that determines the scaling. The suggestion to “Forget about thread-pools, just spawn a new thread…” feels like an invitation to create unstable applications unless other substantive resource management strategies are put into place.
Given that Duke’s “new clothes” woven by Loom are not one-size-fits-all, it would be a mistake to stop developing asynchronous APIs for things such as DNS and JDBC on the unsubstantiated suggestion that Loom virtual threads will make them unnecessary.