Following my previous post, several players tried their HTTP/2 implementation of draft 14 (h2-14) against webtide.com.
A few issues were found and quickly fixed on our side, and this is very good for interoperability.
Having worked many times at implementing specifications, I know that different people interpret the same specification in slightly different ways that may lead to incompatibilities.
@badger and @tatsuhiro_t reported that curl + nghttp2 is working correctly against webtide.com.
On the Firefox side, @todesschaf reported a couple of edge cases that were fixed, so expect a Firefox nightly soon (if not already out?) that supports h2-14.
We are actively working at porting the SPDY Push implementation to HTTP/2, and Firefox should already support HTTP/2 Push, so there will be more interoperability testing to do, which is good.
This work is being done in conjunction with an experimental Servlet API so that web applications will be able to tell the container what resources should be pushed. This experimental push API is scheduled to be defined by the Servlet 4.0 specification, so once again the Jetty project is leading the path like it did for async Servlets, SPDY and SPDY Push.
Why you should care about all this ?
Because SPDY Push can boost your website performance, and more performance means more money for your business.
Interested ? Contact us.
Category: Uncategorized
-
HTTP/2 Interoperability and HTTP/2 Push
-
HTTP/2 Last Call!
The IETF HTTP working group has issued a last call for comments on the proposed HTTP/2 standard, which means that the process has entered the final stage of open community review before the current draft may become an RFC. Jetty has implemented the proposal already and this website is running it already! There is a lot of good in this proposed standard, but I have some deep reservations about some bad and ugly aspects of the protocol.
The Good
HTTP/2 is a child born of the SPDY protocol developed by Google and continues to seek the benefits that have been illuminated by that grand experiment. Specifically:
- The new protocol supports the same semantics as HTTP/1.1 which was recently clarified by RFC7230. This will allow most of the benefits of HTTP/2 to be used by applications transparently simply by upgrading client and server infrastructure, but without any application code changes.
- HTTP/2 is a multiplexed protocol that allows multiple request/response streams to share the same TCP/IP connection. It supports out of order delivery of responses so that it does not suffer from the same Head of Line Blocking issues as HTTP/1.1 pipeline did. Clients will no longer need multiple connections to the same origin server to ensure good quality of service when rendering a page made from many resources, which means a very significant savings in resources needed by the server and also reduces the sticky session problems for load balancers.
- HTTP headers are very verbose and highly redundant. HTTP/2 provides an effective compression algorithm (HPACK) that is tailored to HTTP and avoids many of the security issues with using general purpose compression algorithms over TLS connections. Reduced header size allows many requests to be sent over a newly opened TCP/IP connection without the need to wait for it’s congestion control window to grow to the capacity of the link. This significantly reduces the number of network round trips required to render a page.
- HTTP/2 supports pushed resources, so that an origin server can anticipate requests for associated resources and push them to the clients cache, again saving further network round trips.
You can see from these key features, that HTTP/2 is primarily focused on improving the speed to render a page, which is (as the book of speed points out) a good focus to have. To a lesser extent, the process has also considered through put and server resources, but these have not been key drivers and indeed data rates may even suffer under HTTP/2 and servers need to commit more resources to each connection which may consume much of the savings from fewer connections.
The Bad
While the working groups was chartered to address the misuse of the underlying transport occurring in HTTP/1.1 (eg long polling), it did not make much of the suggestion to coordinate with other working groups regarding the possible future extension of HTTP/2.0 to carry WebSockets semantics. While a websocket over http2 draft has been written, some of the features that draft referenced have subsequently been removed from HTTP/2 and the protocol is primarily focused on providing HTTP semantics.
The proposed protocol does not have a clear separation between a framing layer and the HTTP semantics that can be carried by that layer. I was expecting to see a clear multiplexed, flow controlled framing layer that could be used for many different semantics including HTTP and webSocket. Instead we have a framing protocol aimed primarily at HTTP which to quote the drafts editor:
“What we’ve actually done here is conflate some of the stream control functions with the application semantics functions in the interests of efficiency” — Martin Thomson 8/May/2014
I’m dubious there are significant efficiencies from conflating layers, but even it there are, I believe that such a design will make it much harder to carry WebSocket or other new web semantics over the http2 framing layer. HTTP semantics are hard baked into the framing so intermediaries (routers, hubs, load balancers, firewalls etc.) will be deployed that will have HTTP semantic hard wired. The only way that any future web semantic will be able to be transported over future networks will be to use the trick of pretending to be HTTP, which is exactly the kind of misuse of the underlying transport, that HTTP/2 was intended to address. I know it is difficult to generalise from one example, but today we have both HTTP and WebSocket semantics widely used on the web, so it would have been sensible to consider both examples equally when designing the next generation web framing layer.
An early version of the draft had a header compression algorithm that was highly stateful which meant that a single streams headers had to be encoded/decoded in total before another streams headers could be encoded/decoded. Thus a restriction was put into the protocol to prevent headers being transmitted as multiple frames interleaved with other streams frames. Furthermore, headers are excluded from the multiplexing flow control algorithm because once encoded transmission cannot be delayed without stopping all other encoding/decoding.
The proposed standard has a less stateful compression algorithm so that it is now technically possible to interleave other frames between a fragmented header. It is still not possible to flow control headers, but there is no technical reason that a large header should prevent other streams from progressing. However a concern about denial of service was raised in the working group, and while I argued that it was no worse than without interleaving, the working group was unable to reach consensus to remove the interleaving restriction.
Thus HTTP/2 has a significant incentive for applications to move large data into headers, as this data will effectively take control of the entire multiplexed connection and will be transmitted at full network speed regardless of any http2 flow control windows or other streams that may need to progress. If applications are take up these incentives, then the quality of service offered by the multiplexed connection will suffer and the Head of Line Blocking issue that HTTP/2 was meant to address will return as large headers will hit TCP/IP flow control and stop all streams. When this does happen, clients are likely to do exactly as they did with HTTP/1.1 and ignore any specifications about connection limits and just open multiple connections, so that requests can overtake others that are using large headers to try to take an unfair proportion of a shared connection. This is a catastrophic scenario for servers as not only will we have the increased resource required by HTTP/2 connections, but we will also have the multiple connections required by HTTP/1.
I would like to think that I’m being melodramatic here and predicting a disaster that will never happen. However the history from HTTP/1.1 is that speed is king and that vendors are prepared to break the standards and stress the servers so that applications appear to run faster on their browsers, even if it is only until the other vendors adopt the same protocol abuse. I think we are needlessly setting up the possibility of such a catastrophic protocol fail to protect against a DoS attack vector that must be defended anyway.
The Ugly
There are many aspect of the protocol design that can’t be described as anything but ugly. But unfortunately even though many in the working group agree that they are indeed ugly, the IETF process does not consider aesthetic appeal and thus the current draft is seen to be without issue (even though many have argued that the ugliness means that there will be much misunderstanding and poor implementations of the protocol). I’ll cite one prime example:
A classic case of design ugliness is the END_STREAM flag. The multiplexed streams are comprised of a sequence of frames, some of which can carry the END_STREAM flag to indicate that the stream is ending in that direction. The draft captures the resulting state machine in this simple diagram:
+--------+ PP | | PP ,--------| idle |--------. / | | \ v +--------+ v +----------+ | +----------+ | | | H | | ,---| reserved | | | reserved |---. | | (local) | v | (remote) | | | +----------+ +--------+ +----------+ | | | ES | | ES | | | | H ,-------| open |-------. | H | | | / | | \ | | | v v +--------+ v v | | +----------+ | +----------+ | | | half | | | half | | | | closed | | R | closed | | | | (remote) | | | (local) | | | +----------+ | +----------+ | | | v | | | | ES / R +--------+ ES / R | | | `----------->| |<-----------' | | R | closed | R | `-------------------->| |<--------------------' +--------+ H: HEADERS frame (with implied CONTINUATIONs) PP: PUSH_PROMISE frame (with implied CONTINUATIONs) ES: END_STREAM flag R: RST_STREAM frameThat looks simple enough, a stream is open until an END_STREAM flag is sent/received, at which stage it is half closed, and then when another END_STREAM flag is received/sent the stream is fully closed. But wait there’s more! A stream can continue sending several frame types after a frame with the END_STREAM flag set and these frames may contain semantic data (trailers) or protocol actions that must be acted on (push promises) as well as frames that can just be ignored. This introduces so much complexity that the draft requires 7 paragraphs of dense text to specify the frame handling that must be done once your in the Closed state! It is as if TCP/IP had been specified without CLOSE_WAIT. Worse yet, it is as if you could continue to send urgent data over a socket after it has been closed!
This situation has occurred because of the conflation of HTTP semantics with the framing layer. Instead of END_STREAM being a flag interpreted by the framing layer, the flag is actually a function of frame type and the specific frame type must be understood before the framing layer can consider any flags. With HTTP semantics, it is only legal to end some streams on some particular frame types, so the END_STREAM flag has only been put onto some specific frame types in an attempt to partially enforce good HTTP frame type sequencing (in this case to stop a response stream ending with a push promise). It is a mostly pointless attempt to enforce legal type sequencing because there are an infinite number of illegal sequences that an implementation must still check for and making it impossible to send just some sequences has only complicated the state machine and will make future non-HTTP semantics more difficult. It is a real WTF moment when you realise that valid meta-data can be sent in a frame after a frame with END_STREAM and that you have to interpret the specific frame type to locate the actual end of the stream. It is impossible to write general framing code that handles streams regardless of their type.
The proposed standard allows padding to be added to some specific frame types as a “security feature“, specifically to address “attacks where compressed content includes both attacker-controlled plaintext and secret data (see for example, [BREACH])“. The idea being that padding can be used to hide the affects of compression on sensitive data. But as the draft says “padding is a security feature; as such, its use demands some care” and it turns out to be significant care that is required:
- “Redundant padding could even be counterproductive.”
- “Correct application can depend on having specific knowledge of the data that is being padded.”
- “To mitigate attacks that rely on compression, disabling or limiting compression might be preferable to padding as a countermeasure.”
- “Use of padding can result in less protection than might seem immediately obvious.”
- “At best, padding only makes it more difficult for an attacker to infer length information by increasing the number of frames an attacker has to observe.”
- “Incorrectly implemented padding schemes can be easily defeated.”
So in short, if you are a security genius with precise knowledge of the payload then you might be able to use padding, but it will only slightly mitigate an attack. If you are not a security genius, or you don’t know your what your application payload data is (which is just about everybody), then don’t even think of using padding as you’ll just make things worse. Exactly how an application is meant to tunnel information about the security nature of its data down to the frame handling code of the transport layer is not indicated by the draft and there is no guidance to say what padding to apply other than to say don’t use randomized padding.
I doubt this feature will ever be used for security, but I suspect that it will be used for smuggling illicit data through firewalls.
What Happens Next?
This blog is not a call others to voice support for these concerns in the working group. The IETF process does not work like that, there are no votes and weight of numbers does not count. But on the other hand don’t let me discourage you from participating if you feel you have something to contribute other than numbers.
There has been a big effort by many in the working group to address the concerns that I’ve described here. The process has given critics fair and ample opportunity to voice concerns and to make the case for change. But despite months of dense debate, there is no consensus in the WG that the bad/ugly concerns I have outlined here are indeed issues that need to be addressed. We are entering a phase now where only significant new information will change the destiny of http/2, and that will probably have to be in the form of working code rather than voiced concerns (an application that exploits large headers to the detriment of other tabs/users would be good, or a DoS attack using continuation trailers).
Finally, please note that my enthusiasm for the Good is not dimmed by my concerns for the Bad and Ugly. The Jetty team is well skilled to deal with the Ugly for you and we’ll do our best to hide the Bad as well, so you’ll only see the benefits of the Good. Jetty-9.3 is currently available as a development branch and currently supports draft 14 of HTTP/2 and this website is running on it!. Work is under way on the current draft 14 and that should be supported in a few days. We are reaching out to users and clients who would like to collaborate on evaluating the pros/cons of this emerging standard.
-
HTTP/2 draft 14 is live !
Greg Wilkins (@gregwilkins) and I (@simonebordet) have been working on implementing HTTP/2 draft 14 (h2-14), which is the draft that will probably undergo the “last call” at the IETF.
We will blog very soon with our opinions about HTTP/2 (stay tuned, it’ll be interesting!), but for the time being Jetty proves once again to be a trailblazer when it comes with new web technologies and web protocols.
Jetty started to innovate with Jetty Continuations, that were standardized (with improvements) into Servlet 3.0.
Jetty was one of the first Java server to offer support for asynchronous I/O back in 2006 with Jetty 6.
In 2012 we were the first Java server to implement SPDY, we have written libraries that provide support for NPN in Java (that are now used by many other Java servers that provide SPDY support). We also were the first to implement a completely automatic way of leveraging SPDY Push, that can boost your web site performance.
Today, to my knowledge, we are again the first Java server exposing the implementation of the HTTP/2 protocol, draft 14, live on our own website.
Along with HTTP/2 support, that will be coming in Jetty 9.3, we have also implemented a library that provides support for ALPN in Java (the successor of NPN), allowing every Java application (client or server) to implement HTTP/2 over SSL. This library is already available in the Jetty 9.2.x series. We want other implementers (client and server) to test our HTTP/2 implementation in order to generate feedback about HTTP/2 that can be reported at the IETF.
As of today, both Mozilla Firefox and Google Chrome only support HTTP/2 draft 13 (h2-13). They are keeping the pace at implementing new drafts, so expect both browsers to offer draft 14 support in matter of days (in their nightly/unstable versions). When that will happen, you will be able to use those browsers to connect to our HTTP/2 enabled website.
The Jetty project offers not only a server, but a HTTP/2 client as well. You can take a look at how it’s used to connect to a HTTP/2 server here.
Where is it ? https://webtide.com.
Lastly, contact us for any news or information about what Jetty can do for you in the realms of async I/O, PubSub over the web (via CometD), SPDY and HTTP/2.
-
RFC7230 for HTTP 1.1, 1.3 or 2.0?
The httpbis working group of the IETF has release RFC7230 (HTTP/1.1) which obsoletes the long serving RFC2616 (HTTP/1.1), which itself obsoleted the ill fated RFC2068 (HTTP/1.1), which had attempted to replace RFC1945 (HTTP/1.0). So with the 4th version of a HTTP/1.x specification, some might argue that we really should be talking about HTTP/1.3 rather than 3 versions on HTTP/1.1!
So what is going on? Why a new specification for an existing protocol, specially when the same working group is also deep into considerations of http2!
The new RFC (and several companion RFCs) are not trying specifying a new protocol or even a new version of the HTTP protocol. It is essentially a clarification exercise to write down a specification that captures the best recommended practises for how HTTP/1.1 has actually been implemented. Specifically the httpbis charter was to:
- Incorporate errata and updates (e.g., references, IANA registries, ABNF)
- Fix editorial problems which have led to misunderstandings of the specification
- Clarify conformance requirements
- Remove known ambiguities where they affect interoperability
- Clarify existing methods of extensibility
- Remove or deprecate those features that are not widely implemented and also unduly affect interoperability
- Where necessary, add implementation advice
- Document the security properties of HTTP and its associated mechanisms (e.g., Basic and Digest authentication, cookies, TLS) for common applications
The reason this was necessary, is that no spec is perfect and RFC2616 did have a number of ambiguities, failed features and security problems. This has made it very difficult for a well written server because of the sage advice of being strict in what you generate but forgiving in what you parse. A forgiving HTTP Server written against RFC2616 has to cope with a wide range of requests and can often be tricked into seeing requests where there are none.
RFC7230 gives a server permission and advice to be a little bit less forgiving, thus allowing simple/faster code with less edge cases and thus less bugs and/or security exploits. You can see a good summary of these changes in the Changes from RFC2616 section. Jetty will be following 7230 advice from releases 9.3 and/or 10.0 and I’m very pleased to have already removed support for 0.9, continuation headers and arbitrary white space in headers.
But why is this needed if HTTP/2 is soon to arrive? Well HTTP/1 is not going away any time soon. It has taken more than 20 years to remove HTTP/0.9 support and I expect at least a similar time before HTTP/1 is relegated. Actually given the current complexity of HTTP/2, HTTP/1 may need another protocol to be standardised before it is replaced in some environments. But also HTTP2 is only defining a new transport for HTTP semantics, so RFC7230 will still be relevant and required in a HTTP/2 environment.
The authors and contributors to RFC7230 have done a great job and the Jetty team has already started work on both RFC7230 as well as HTTP/2. You can see the progress in the jetty-http2 branch, which is currently labelled 10.0.0-SNAPSHOT, but may become 9.3.0.
-
Jetty 9.2.0 Released
The Webtide Jetty development team is pleased to announce that we have released Jetty 9.2.0, which is available for download from eclipse or maven central.
Along with numerous fixes and improvements, this release has some exciting new features.Java 8 Support
Jetty 9.2.0 has been updated to run well with Java 8, including updating dependencies such as ASM. While Jetty does not yet take advantage of any Java 8 language features, the server does run on the JVM 8, so that improvements in the JIT and garbage collector are available to Jetty users.
Quick Start
We have already announced the quickstart mechanism that resulted from our collaboration with Google AppEngine. The quick start mechanism allows the start up time of web applications to be reduced to a few hundred milliseconds. For cloud system like AppEngine, this reduced start time can save vital resources as it allows web applications to be started on demand within the acceptable response time of a single request.
Apache JSP/JSTL
The 9.2 release has switched to using the Apache version of Jasper for JSP and JSTL. Early releases of Jetty used these implementations, but switched to Glassfish when it became the reference implementation. However the Apache version is now more rigorously maintained and hence we have switched back. Currently we are using a slightly modified version of 8.0.3, however our modifications have been contributed back to apache and have been accepted for their 8.0.9 release, so we will soon switch to using a standard jar from Apache.
Async I/O Proxying
The ProxyServlet class implements a flexible reverse proxy by leveraging Jetty 9’s asynchronous HttpClient. Before Jetty 9.2.0 the ProxyServlet implementation was reading data from the downstream client and writing data to the downstream client using the blocking APIs of, respectively, the request ServletInputStream and the response ServletOutputStream.
From Jetty 9.2.0 a new implementation has been introduced, AsyncProxyServlet, that leverages the asynchronous I/O features of Servlet 3.1 to read from and write to the downstream client, therefore making possible to be 100% fully asynchronous. This means better scalability and less resources used by the server to proxy the requests/responses.
Users that are bound to use Servlet 3.0 can continue to use ProxyServlet; you can leverage AsyncProxyServlet’s scalability by updating your web application to use Servlet 3.1, and by deploying it in Jetty 9.2.0 or greater.Async FastCGI
The primary beneficiary of AsyncProyServlet is Jetty’s FastCGI support, which we are using in this same web site and that we have discussed here and here.
By using AsyncProyServlet, the FastCGI proxying has become even more efficient and allows Jetty to run with a minimum of memory (just 20 MiB of occupied heap) and minimum of threads.
With Jetty 9.2.0 you can deploy your PHP applications leveraging Jetty’s scalability and SPDY support (along with Jetty’s SPDY Push) to make your web sites quick and responsive.ALPN Support
Jetty 9.2.0 provides an implementation of ALPN, the Application Layer Protocol Negotiation specification.
ALPN is the successor to NPN (the Next Protocol Negotiation) and is implemented for both JDK 7 and JDK 8. ALPN will be used by SPDY and HTTP 2.0 to negotiate the application protocol of a TLS connection.
Users using NPN and JDK 7 may continue to do so, or update to ALPN. Users of JDK 8 will only be able to use ALPN.Multiple Jetty base directories
The Jetty 9.0 series introduced the $jetty.base and $jetty.home mechanism, which allows local configuration modifications to all be put into a base directory which is kept separate from the home directory, which can be kept as an unmodified jetty distribution. This allows simple upgrades between jetty versions without the need to refactor your configuration. Jetty 9.2 has now extended this mechanism to allow multiple directories. You can now have layers of configuration, your your enterprise, your cluster, your node and your webapp, or however you wish to layer your configuration.
-
Jetty 9.1.4 Open Sources FastCGI Proxy
I wrote in the past about the support that was added to Jetty 9.1 to proxy HTTP requests to a FastCGI server.
A typical configuration to serve PHP applications such as WordPress or Drupal is to put Apache or Nginx in the front and have them proxy the HTTP requests to, typically,php-fpm(a FastCGI server included in the PHP distribution), which in turn runs the PHP scripts that generate HTML.
Jetty’s support for FastCGI proxying has been kept private until now.
With the release of Jetty 9.1.4 it is now part of the main Jetty distribution, released under the same license (Apache License or Eclipse Public License) as Jetty.
Since we like to eat our own dog food, Jetty is currently serving the pages of this blog (which is WordPress) using Jetty 9.1.4 and the newly released FastCGI module.
And it is doing so via SPDY, rather than HTTP, allowing you to serve Java EE Web Applications and PHP Web Applications from the same Jetty instance and leveraging the benefits that the SPDY protocol brings to the Web.
For further information and details on how to use this new module, please check the Jetty FastCGI documentation.
Enjoy ! -
Jetty 9 Quick Start
The auto discovery features of the Servlet specification can make deployments slow and uncertain. Working in collaboration with Google AppEngine, the Jetty team has developed the Jetty quick start mechanism that allows rapid and consistent starting of a Servlet server. Google AppEngine has long used Jetty for it’s footprint and flexibility, and now fast and predictable starting is a new compelling reason to use jetty in the cloud. As Google App Engine is specifically designed with highly variable, bursty workloads in mind – rapid start up time leads directly to cost-efficient scaling.
Servlet Container Discovery Features
The last few iterations of the Servlet 3.x specification have added a lot of features related to making development easier by auto discovery and configuration of Servlets, Filters and frameworks:
Discover / From: Selected
Container
JarsWEB-INF/
classes/
*WEB-INF/
lib/
*.jarAnnotated Servlets & Filters Y Y Y web.xml fragments Y Y ServletContainerInitializers Y Y Classes discoverd by HandlesTypes Y Y Y JSP Taglib descriptors Y Y Slow Discovery
Auto discovery of Servlet configuration can be useful during the development of a webapp as it allows new features and frameworks to be enabled simply by dropping in a jar file. However, for deployment, the need to scan the contents of many jars can have a significant impact of the start time of a webapp. In the cloud, where server instances are often spun up on demand, having a slow start time can have a big impact on the resources needed.
Consider a cluster under load that determines that an extra node is desirable, then every second the new node spends scanning its own classpath for configuration is a second that the entire cluster is overloaded and giving less than optimal performance. To counter the inability to quickly bring on new instances, cluster administrators have to provision more idle capacity that can handle a burst in load while more capacity is brought on line. This extra idle capacity is carried for all time while the application is running and thus a slowly starting server increases costs over the whole application deployment.
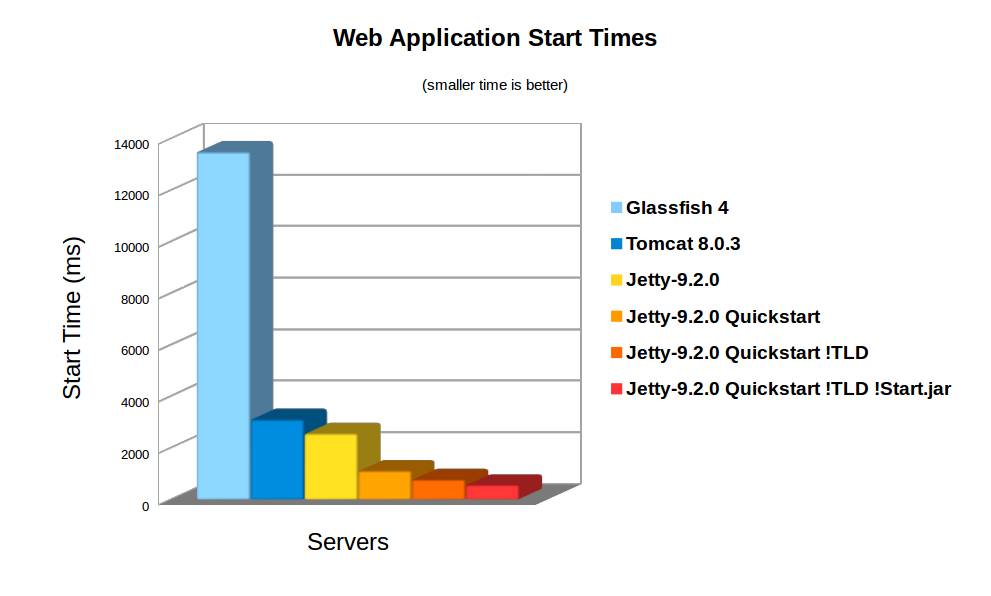
On average server hardware, a moderate webapp with 36 jars (using spring, jersey & jackson) took over 3,158ms to deploy on Jetty 9. Now this is pretty fast and some Servlet containers (eg Glassfish) take more time to initialise their logging. However 3s is still over a reasonable thresh hold for making a user wait whilst dynamically starting an instance. Also many webapps now have over 100 jar dependencies, so scanning time can be a lot longer.
Using the standard meta-data complete option does not significantly speed up start times, as TLDs and HandlersTypes classes still must be discovered even with meta data complete. Unpacking the war file saves a little more time, but even with both of these, Jetty still takes 2,747ms to start.
Unknown Deployment
Another issue with discovery is that the exact configuration of the a webapp is not fully known until runtime. New Servlets and frameworks can be accidentally deployed if jar files are upgraded without their contents being fully investigated. This give some deployers a large headache with regards to security audits and just general predictability.
It is possible to disable some auto discovery mechanisms by using the meta-data-complete setting within web.xml, however that does not disable the scanning of HandlesTypes so it does not avoid the need to scan, nor avoid auto deployment of accidentally included types and annotations.
Jetty 9 Quickstart
From release 9.2.0 of Jetty, we have included the quickstart module that allows a webapp to be pre-scanned and preconfigured. This means that all the scanning is done prior to deployment and all configuration is encoded into an effective web.xml, called WEB-INF/quickstart-web.xml, which can be inspected to understand what will be deployed before deploying.
Not only does the quickstart-web.xml contain all the discovered Servlets, Filters and Constraints, but it also encodes as context parameters all discovered:
- ServletContainerInitializers
- HandlesTypes classes
- Taglib Descriptors
With the quickstart mechanism, jetty is able to entirely bypass all scanning and discovery modes and start a webapp in a predictable and fast way.
Using Quickstart
To prepare a jetty instance for testing the quickstart mechanism is extremely simple using the jetty module system. Firstly, if JETTY_HOME is pointing to a jetty distribution >= 9.2.0, then we can prepare a Jetty instance for a normal deployment of our benchmark webapp:
> JETTY_HOME=/opt/jetty-9.2.0.v20140526 > mkdir /tmp/demo > cd /tmp/demo > java -jar $JETTY_HOME/start.jar --add-to-startd=http,annotations,plus,jsp,deploy > cp /tmp/benchmark.war webapps/
and we can see how long this takes to start normally:
> java -jar $JETTY_HOME/start.jar 2014-03-19 15:11:18.826:INFO::main: Logging initialized @255ms 2014-03-19 15:11:19.020:INFO:oejs.Server:main: jetty-9.2.0.v20140526 2014-03-19 15:11:19.036:INFO:oejdp.ScanningAppProvider:main: Deployment monitor [file:/tmp/demo/webapps/] at interval 1 2014-03-19 15:11:21.708:INFO:oejsh.ContextHandler:main: Started o.e.j.w.WebAppContext@633a6671{/benchmark,file:/tmp/jetty-0.0.0.0-8080-benchmark.war-_benchmark-any-8166385366934676785.dir/webapp/,AVAILABLE}{/benchmark.war} 2014-03-19 15:11:21.718:INFO:oejs.ServerConnector:main: Started ServerConnector@21fd3544{HTTP/1.1}{0.0.0.0:8080} 2014-03-19 15:11:21.718:INFO:oejs.Server:main: Started @2579msSo the JVM started and loaded the core of jetty in 255ms, but another 2324 ms were needed to scan and start the webapp.
To quick start this webapp, we need to enable the quickstart module and use an example context xml file to configure the benchmark webapp to use it:
> java -jar $JETTY_HOME/start.jar --add-to-startd=quickstart > cp $JETTY_HOME/etc/example-quickstart.xml webapps/benchmark.xml > vi webapps/benchmark.xml
The benchmark.xml file should be edited to point to the benchmark.war file:
<?xml version="1.0" encoding="ISO-8859-1"?> <!DOCTYPE Configure PUBLIC "-//Jetty//Configure//EN" "http://www.eclipse.org/jetty/configure_9_0.dtd"> <Configure class="org.eclipse.jetty.quickstart.QuickStartWebApp"> <Set name="autoPreconfigure">true</Set> <Set name="contextPath">/benchmark</Set> <Set name="war"><Property name="jetty.webapps" default="."/>/benchmark.war</Set> </Configure>
Now the next time the webapp is run, it will be preconfigured (taking a little bit longer than normal start):
> java -jar $JETTY_HOME/start.jar 2014-03-19 15:21:16.442:INFO::main: Logging initialized @237ms 2014-03-19 15:21:16.624:INFO:oejs.Server:main: jetty-9.2.0.v20140526 2014-03-19 15:21:16.642:INFO:oejdp.ScanningAppProvider:main: Deployment monitor [file:/tmp/demo/webapps/] at interval 1 2014-03-19 15:21:16.688:INFO:oejq.QuickStartWebApp:main: Quickstart Extract file:/tmp/demo/webapps/benchmark.war to file:/tmp/demo/webapps/benchmark 2014-03-19 15:21:16.733:INFO:oejq.QuickStartWebApp:main: Quickstart preconfigure: o.e.j.q.QuickStartWebApp@54318a7a{/benchmark,file:/tmp/demo/webapps/benchmark,null}(war=file:/tmp/demo/webapps/benchmark.war,dir=file:/tmp/demo/webapps/benchmark) 2014-03-19 15:21:19.545:INFO:oejq.QuickStartWebApp:main: Quickstart generate /tmp/demo/webapps/benchmark/WEB-INF/quickstart-web.xml 2014-03-19 15:21:19.879:INFO:oejsh.ContextHandler:main: Started o.e.j.q.QuickStartWebApp@54318a7a{/benchmark,file:/tmp/demo/webapps/benchmark,AVAILABLE} 2014-03-19 15:21:19.893:INFO:oejs.ServerConnector:main: Started ServerConnector@63acac21{HTTP/1.1}{0.0.0.0:8080} 2014-03-19 15:21:19.894:INFO:oejs.Server:main: Started @3698msAfter preconfiguration, on all subsequent starts it will be quick started:
> java -jar $JETTY_HOME/start.jar 2014-03-19 15:21:26.069:INFO::main: Logging initialized @239ms 2014-03-19 15:21:26.263:INFO:oejs.Server:main: jetty-9.2.0-SNAPSHOT 2014-03-19 15:21:26.281:INFO:oejdp.ScanningAppProvider:main: Deployment monitor [file:/tmp/demo/webapps/] at interval 1 2014-03-19 15:21:26.941:INFO:oejsh.ContextHandler:main: Started o.e.j.q.QuickStartWebApp@559d6246{/benchmark,file:/tmp/demo/webapps/benchmark/,AVAILABLE}{/benchmark/} 2014-03-19 15:21:26.956:INFO:oejs.ServerConnector:main: Started ServerConnector@4a569e9b{HTTP/1.1}{0.0.0.0:8080} 2014-03-19 15:21:26.956:INFO:oejs.Server:main: Started @1135msSo quickstart has reduced the start time from 3158ms to approx 1135ms!
More over, the entire configuration of the webapp is visible in webapps/benchmark/WEB-INF/quickstart-web.xml. This file can be examine and all the deployed elements can be easily audited.
Starting Faster!
Avoiding TLD scans
The jetty 9.2 distribution switched to using the apache Jasper JSP implementation from the glassfish JSP engine. Unfortunately this JSP implementation will always scan for TLDs, which turns out takes a significant time during startup. So we have modified the standard JSP initialisation to skip TLD parsing altogether if the JSPs have been precompiled.
To let the JSP implementation know that all JSPs have been precompiled, a context attribute needs to be set in web.xml:
<context-param> <param-name>
org.eclipse.jetty.jsp. precompiled</param-name> < param-value>true</param-value> </context-param> This is done automagically if you use the Jetty Maven JSPC plugin. Now after the first run, the webapp starts in 797ms:
> java -jar $JETTY_HOME/start.jar 2014-03-19 15:30:26.052:INFO::main: Logging initialized @239ms 2014-03-19 15:30:26.245:INFO:oejs.Server:main: jetty-9.2.0.v20140526 2014-03-19 15:30:26.260:INFO:oejdp.ScanningAppProvider:main: Deployment monitor [file:/tmp/demo/webapps/] at interval 1 2014-03-19 15:30:26.589:INFO:oejsh.ContextHandler:main: Started o.e.j.q.QuickStartWebApp@414fabe1{/benchmark,file:/tmp/demo/webapps/benchmark/,AVAILABLE}{/benchmark/} 2014-03-19 15:30:26.601:INFO:oejs.ServerConnector:main: Started ServerConnector@50473913{HTTP/1.1}{0.0.0.0:8080} 2014-03-19 15:30:26.601:INFO:oejs.Server:main: Started @797msBypassing start.jar
The jetty start.jar is a very powerful and flexible mechanism for constructing a classpath and executing a configuration encoded in jetty XML format. However, this mechanism does take some time to build the classpath. The start.jar mechanism can be bypassed by using the –dry-run option to generate and reuse a complete command line to start jetty:
> RUN=$(java -jar $JETTY_HOME/start.jar --dry-run) > eval $RUN 2014-03-19 15:53:21.252:INFO::main: Logging initialized @41ms 2014-03-19 15:53:21.428:INFO:oejs.Server:main: jetty-9.2.0.v20140526 2014-03-19 15:53:21.443:INFO:oejdp.ScanningAppProvider:main: Deployment monitor [file:/tmp/demo/webapps/] at interval 1 2014-03-19 15:53:21.761:INFO:oejsh.ContextHandler:main: Started o.e.j.q.QuickStartWebApp@7a98dcb{/benchmark,file:/tmp/demo/webapps/benchmark/,AVAILABLE}{file:/tmp/demo/webapps/benchmark/} 2014-03-19 15:53:21.775:INFO:oejs.ServerConnector:main: Started ServerConnector@66ca206e{HTTP/1.1}{0.0.0.0:8080} 2014-03-19 15:53:21.776:INFO:oejs.Server:main: Started @582msClassloading?
With the quickstart mechanism, the start time of the jetty server is dominated by classloading, with over 50% of the CPU being profiled within URLClassloader, and the next hot spot is 4% in XML Parsing. Thus a small gain could be made by pre-parsing the XML into byte code calls, but any more significant progress will probably need examination of the class loading mechanism itself. We have experimented with combining all classes to a single jar or a classes directory, but with no further gains.
Conclusion
The Jetty-9 quick start mechanism provides almost an order of magnitude improvement is start time. This allows fast and predictable deployment, making Jetty the ideal server to be used in dynamic clouds such as Google App Engine.
-
Jetty 9 Modules and Base
Jetty has always been a highly modular project, which can be assembled in an infinite variety of ways to provide exactly the server/client/container that you required. With the recent Jetty 9.1 releases, we have added some tools to greatly improve the usability of configuring the modules used by a server.
Jetty now has the concept of a jetty home directory, where the standard distribution is installed, and a jetty base directory, which contains just the configuration of a specific instance of jetty. With this division, updating to a new version of jetty can be as simple as just updating the reference to jetty home and all the configuration in jetty base will apply.
Defining a jetty home is trivial. You simply need to unpack the jetty distribution. For this demonstration, we’ll also define an environment variable:
export JETTY_HOME=/opt/jetty-9.1.3.v20140225/
Creating a jetty base is also easy, as it is just a matter of creating a directory and using the jetty start.jar tools to enable the modules that you want. For example to create a jetty base with a HTTP and SPDY connector, JMX and a deployment manager (to scan webapps directory), you can do:
mkdir /tmp/demo cd /tmp/demo java -jar $JETTY_HOME/start.jar --add-to-startd=http,spdy,jmx,deploy
You now have a jetty base defining a simple server ready to run. Note that all the required directories have been created and additional dependencies needed for SPDY are downloaded:
demo ├── etc │ └── keystore ├── lib │ └── npn ├── start.d │ ├── deploy.ini │ ├── http.ini │ ├── jmx.ini │ ├── npn.ini │ ├── server.ini │ ├── spdy.ini │ └── ssl.ini └── webapps
All you need do is copy in your webapp and start the server:
cp ~/somerepo/async-rest.war webapps/java -jar $JETTY_HOME/start.jar
You can see details of the modules available and the current configuration using the commands:
java -jar $JETTY_HOME/start.jar --list-modules java -jar $JETTY_HOME/start.jar --list-confi
You can see a full demonstration of the jetty base and module capabilities in the following webinar:
Note also that with the Jetty 9.0.4, modules will be available to replace the glassfish versions of JSP and JSTL with the apache release. -
How to install JIRA 6.1 in Jetty 9.1
Atlassian JIRA is a very good issue tracking system. Many open source projects use it, including our own CometD project and most notably OpenJDK.
While Atlassian supports JIRA on Tomcat, JIRA runs in Jetty as well, and can benefit of Jetty’s support for SPDY.
Below you can find the instructions on how to setup JIRA 6.1.5 in Jetty 9.1.0 with HTTP and SPDY support on Linux.1. Download JIRA’s WAR version
JIRA can be downloaded in two versions: the distro installer version (the default download from JIRA’s website), and the distro WAR version. You need to download the distro WAR version by clicking on “All JIRA Download Options” on the download page.
2. Build the JIRA WAR
Unpack the JIRA distro WAR file. It will create a directory called
atlassian-jira-<version>-warreferred to later as$JIRA_DISTRO_WAR.2.1 Specify the JIRA HOME directory
$ cd $JIRA_DISTRO_WAR/edit-webapp/WEB-INF/classes/ $ vi jira-application.properties
The
jira-application.propertiesfile contains just one property:jira.home =
You need to specify the full path of your JIRA home directory, for example:
jira.home = /var/jira
2.2 Change the JNDI name for
UserTransactionThe JIRA configuration files come with a non standard JNDI name for the
UserTransactionobject.
This non standard name works in Tomcat, but it’s wrong for any other compliant Servlet container, so it must be modified to the standard name to work in Jetty.$ cd $JIRA_DISTRO_WAR/edit-webapp/WEB-INF/classes/ $ vi entityengine.xml
You need to search in the
entityengine.xmlfile for two lines inside the<transaction-factory>element:<transaction-factory class="org.ofbiz.core.entity.transaction.JNDIFactory"> <user-transaction-jndi jndi-server-name="default" jndi-name="java:comp/env/UserTransaction"/> <-- First line to change <transaction-manager-jndi jndi-server-name="default" jndi-name="java:comp/env/UserTransaction"/> <-- Second line to change </transaction-factory>You need to change the
jndi-nameattribute from the non standard namejava:comp/env/UserTransactionto the standard namejava:comp/UserTransaction. You have to remove the/envpart in the JNDI name in both lines.2.3 Execute the build
At this point you need to build the JIRA WAR file, starting from the JIRA distro WAR file:
$ cd $JIRA_DISTRO_WAR $ ./build.sh
When the build completes, it generates a file called
$JIRA_DISTRO_WAR/dist-generic/atlassian-jira-<version>.war. The build also generates a Tomcat version, but you need to use the generic version of the WAR.3. Install Jetty 9.1
Download Jetty 9.1 and unpack it in the directory of your choice, for example
/opt, so that Jetty will be installed in a directory such as/opt/jetty-distribution-9.1.0.v20131115referred to later as$JETTY_HOME.
We will not modify any file in this directory, but only refer to it to start Jetty.4. Setup the database
JIRA requires a relational database to work. Follow the instructions on how to setup a database for JIRA.
When you run JIRA for the first time, it will ask you for the database name, user name and password.5. Setup the Jetty Base
Jetty 9.1 introduced a mechanism to separate the Jetty installation directory (
$JETTY_HOME) from the directory where you configure your web applications, referred to as$JETTY_BASE. The documentation offers more information about this mechanism.
Create the Jetty base directory in the location you prefer, for example/var/www/jira, referred to later as$JETTY_BASE.$ mkdir -p /var/www/jira
5.1 Setup the transaction manager
JIRA requires a transaction manager to work, and Jetty does not provide one out of the box. However, it’s not difficult to provide support for it.
You will use Atomikos’ TransactionsEssentials, an open source transaction manager released under the Apache 2 License.
For a transaction manager to work, you need the transaction manager jars (in this case Atomikos’) and you need to instruct Jetty to bind aUserTransactionobject in JNDI.5.1.1 Create the Jetty module definition
You can use a Jetty module to define the transaction manager support in Jetty following these instructions:
$ cd $JETTY_BASE $ mkdir modules $ vi modules/atomikos.mod
Create a file in the
modulesdirectory calledatomikos.modwith this content:# Atomikos Module [depend] plus resources [lib] lib/atomikos/*.jar [xml] etc/jetty-atomikos.xml
This file states that the
atomikosmodule depends on Jetty’s built-inplusandresourcesmodules, that requires all the jars in the$JETTY_BASE/lib/atomikosdirectory in the classpath, and that it is configured by a file in the$JETTY_BASE/etcdirectory calledjetty-atomikos.xml.5.1.2 Download the module dependencies
Create the
lib/atomikosdirectory:$ cd $JETTY_BASE $ mkdir -p lib/atomikos
and save into it the following files, downloaded from Maven Central from this location (at the time of this writing the latest Atomikos version is 3.9.1):
- atomikos-util.jar
- transactions-api.jar
- transactions.jar
- transactions-jta.jar
- transactions-jdbc.jar
5.1.3 Create the module XML file
Create the
etcdirectory:$ cd $JETTY_BASE $ mkdir etc $ vi etc/jetty-atomikos.xml
Create a file in the
etcdirectory calledjetty-atomikos.xmlwith this content:<?xml version="1.0"?> <!DOCTYPE Configure PUBLIC "-//Jetty//Configure//EN" "http://www.eclipse.org/jetty/configure_9_0.dtd"> <Configure id="Server" class="org.eclipse.jetty.server.Server"> <New class="org.eclipse.jetty.plus.jndi.Transaction"> <Arg> <New class="com.atomikos.icatch.jta.UserTransactionImp" /> </Arg> </New> </Configure>5.1.4 Create the
jta.propertiesfileCreate the
resourcesdirectory:$ cd $JETTY_BASE $ mkdir resources $ vi resources/jta.properties
Create a file in the
resourcesdirectory calledjta.propertieswith this content:com.atomikos.icatch.service = com.atomikos.icatch.standalone.UserTransactionServiceFactory
This file configures the Atomikos transaction manager; you can read about other supported properties in the Atomikos documentation, but the one specified above is sufficient.
5.2 Setup the JDBC driver
JIRA is able to autoconfigure the database connectivity during the first run, but it requires the JDBC driver to be available.
Create thelib/extdirectory:$ cd $JETTY_BASE $ mkdir -p lib/ext
Download the JDBC driver and copy it in the
$JETTY_BASE/lib/extdirectory.
For example, if you use MySQL you would copy the JDBC driver as$JETTY_BASE/lib/ext/mysql-connector-java-5.1.27.jar.5.3 Deploy the JIRA WAR
Create the
webappsdirectory:$ cd $JETTY_BASE $ mkdir webapps
Copy the JIRA generic WAR created at step 2.3 in the
webappsdirectory:$ cd $JETTY_BASE $ cp $JIRA_DISTRO_WAR/dist-generic/atlassian-jira-<version>.war webapps/
5.5 Create the Jetty
start.inifileJetty 9.1 uses the
$JETTY_BASE/start.inifile to configure the modules that will be activated when Jetty starts. You need:- the
atomikosmodule that you created above - Jetty’s built-in
extmodule, to have the JDBC driver in classpath - Jetty’s built-in
deploymodule, to deploy web applications present in thewebappsdirectory - Jetty’s built-in
jspmodule, for JSP support required by JIRA - Jetty’s built-in
httpmodule, to have Jetty listen for HTTP requests
Create the
start.inifile:$ cd $JETTY_BASE $ vi start.ini
with the following content:
--module=atomikos --module=ext --module=deploy --module=jsp --module=http jetty.port=8080
The last property instructs Jetty to listen on port 8080 for HTTP requests.
6. Start Jetty
At this point you are ready to start Jetty.
If you are using JDK 7, JIRA requires a larger than default permanent generation, and a larger than default heap as well to work properly.
Start Jetty in the following way:$ cd $JETTY_BASE $ java -Xmx1g -XX:MaxPermSize=256m -jar $JETTY_HOME/start.jar
Be patient, JIRA may be slow to start up.
7. SPDY support
In order to enable SPDY support, you need to deploy your site over SSL. In order to do so, you need to have a valid X509 certificate for your site.
Follow the SSL documentation for details about how to configure SSL for your site.
If you want to just try SPDY locally on your computer, you can use a self-signed certificate stored in a keystore.7.1 Create the keystore
Create a keystore with a self-signed certificate:
$ cd $JETTY_BASE $ keytool -genkeypair -keystore etc/keystore -keyalg RSA -dname "cn=localhost" -storepass <password> -keypass <password>
The certificate must be stored in the
$JETTY_BASE/etc/keystorefile so that it will be automatically picked up by Jetty (this is configurable via thejetty.keystoreproperty if you prefer a different location).7.2 Setup the NPN jar
SPDY also requires the NPN jar, that depends on the JDK version you are using.
Please refer to the NPN versions table to download the right NPN jar for your JDK.
Create thelib/npndirectory:$ cd $JETTY_BASE $ mkdir -p lib/npn
Download the right version of the NPN boot jar from this location and save it in the
$JETTY_BASE/lib/npndirectory.7.3 Modify the
start.inifileModify the
$JETTY_BASE/start.inifile to have the following content:--module=atomikos --module=ext --module=deploy --module=jsp --module=spdy spdy.port=8443 jetty.keystore.password=<password> jetty.keymanager.password=<password> jetty.truststore.password=<password>
The
httpmodule has been replaced by thespdymodule, and so has the configuration property for the port to listen to.
There are new properties that specifies the password you used to create the keystore in various ways to obfuscate them to avoid that they appear in clear in configuration files.7.4 Start Jetty with SPDY support
$ cd $JETTY_BASE $ java -Xbootclasspath/p:lib/npn/npn-boot-<version>.jar -Xmx1g -XX:MaxPermSize=256m -jar $JETTY_HOME/start.jar
Conclusions
We have seen how JIRA 6.1 can be deployed to Jetty 9.1 following the steps above.
The advantage of using Jetty are the support for SPDY, which will improve the performance of the website, the high scalability of Jetty and the flexibility of Jetty in defining modules and starting only the modules needed by your web applications, and no more.
One disadvantage over Tomcat is the lack of out-of-the-box support for a transaction manager. While the step to add this support are not complicated, we recognize that it will be great if the transaction manager module would be available out-of-the-box.
We are working on providing such feature to improve Jetty, so stay tuned ! -
Jetty-9 Iterating Asynchronous Callbacks
While Jetty has internally used asynchronous IO since 7.0, Servlet 3.1 has added asynchronous IO to the application API and Jetty-9.1 now supports asynchronous IO in an unbroken chain from application to socket. Asynchronous APIs can often look intuitively simple, but there are many important subtleties to asynchronous programming and this blog looks at one important pattern used within Jetty. Specifically we look at how an iterating callback pattern is used to avoid deeps stacks and unnecessary thread dispatches.
Asynchronous Callback
Many programmers wrongly believe that asynchronous programming is about Futures. However Futures are a mostly broken abstraction and could best be described as a deferred blocking API rather than an Asynchronous API. True asynchronous programming is about callbacks, where the asynchronous operation calls back the caller when the operation is complete. A classic example of this is the NIO AsynchronousByteChannel write method:
<A> void write(ByteBuffer src, A attachment, CompletionHandler<Integer,? super A> handler); public interface CompletionHandler<V,A> { void completed(V result, A attachment); void failed(Throwable exc, A attachment); }
With an NIO asynchronous write, a CompletionHandler instance is pass that is called back once the write operation has completed or failed. If the write channel is congested, then no calling thread is held or blocked whilst the operation waits for the congestion to clear and the callback will be invoked by a thread typically taken from a thread pool.
The Servlet 3.1 Asynchronous IO API is syntactically very different, but semantically similar to NIO. Rather than have a callback when a write operation has completed the API has a WriteListener API that is called when a write operation can proceed without blocking:
public interface WriteListener extends EventListener { public void onWritePossible() throws IOException; public void onError(final Throwable t); }Whilst this looks different to the NIO write CompletionHandler, effectively a write is possible only when the previous write operation has completed, so the callbacks occur on essentially the same semantic event.
Callback Threading Issues
So that asynchronous callback concept looks pretty simple! How hard could it be to implement and use! Let’s consider an example of asynchronously writing the data obtained from an InputStream. The following WriteListener can achieve this:
public class AsyncWriter implements WriteListener { private InputStream in; private ServletOutputStream out; private AsyncContext context; public AsyncWriter(AsyncContext context, InputStream in, ServletOutputStream out) { this.context=context; this.in=in; this.out=out; } public void onWritePossible() throws IOException { byte[] buf = new byte[4096]; while(out.isReady()) { int l=in.read(buf,0,buf.length); if (l<0) { context.complete(); return; } out.write(buf,0,l); } } ... }Whenever a write is possible, this listener will read some data from the input and write it asynchronous to the output. Once all the input is written, the asynchronous Servlet context is signalled that the writing is complete.
However there are several key threading issues with a WriteListener like this from both the caller and callee’s point of view. Firstly this is not entirely non blocking, as the read from the input stream can block. However if the input stream is from the local file system and the output stream is to a remote socket, then the probability and duration of the input blocking is much less than than of the output, so this is substantially non-blocking asynchronous code and thus is reasonable to include in an application. What this means for asynchronous operations providers (like Jetty), is that you cannot trust any code you callback to not block and thus you cannot use an important thread (eg one iterating over selected keys from a Selector) to do the callback, else an application may inadvertently block other tasks from proceeding. Thus Asynchronous IO Implementations thus must often dispatch a thread to perform a callback to application code.
Because dispatching threads is expensive in both CPU and latency, Asynchronous IO implementations look for opportunities to optimise away thread dispatches to callbacks. There Servlet 3.1 API has by design such an optimisation with the out.isReady() call that allows iteration of multiple operations within the one callback. A dispatch to onWritePossible only happens when it is required to avoid a blocking write and often many write iterations can proceed within a single callback. An NIO CompletionHandler based implementation of the same task is only able to perform one write operation per callback and must wait for the invocation of the complete handler for that operation before proceeding:
public class AsyncWriter implements CompletionHandler<Integer,Void> { private InputStream in; private AsynchronousByteChannel out; private CompletionHandler<Void,Void> complete; private byte[] buf = new byte[4096]; public AsyncWriter(InputStream in, AsynchronousByteChannel out, CompletionHandler<Void,Void> complete) { this.in=in; this.out=out; this.complete=complete; completed(0,null); } public void completed(Integer w,Void a) throws IOException { int l=in.read(buf,0,buf.length); if (l<0) complete.completed(null,null); else out.write(ByteBuffer.wrap(buf,0,l),this); } ... }Apart from an unrelated significant bug (left as an exercise for the reader to find), this version of the AsyncWriter has a significant threading challenge. If the write can trivially completes without blocking, should the callback to CompletionHandler be dispatched to a new thread or should it just be called from the scope of the write using the caller thread? If a new thread is always used, then many many dispatch delays will be incurred and throughput will be very low. But if the callback is invoked from the scope of the write call, then if the callback does a re-entrant call to write, it may call a callback again which calls write again etc. etc. and a very deep stack will result and often a stack overflow can occur.
The JVM’s implementation of NIO resolves this dilemma by doing both! It performs the callback in the scope of the write call until it detects a deep stack, at which time it dispatches the callback to a new thread. While this does work, I consider it a little bit of the worst of both worlds solution: you get deep stacks and you get dispatch latency. Yet it is an accepted pattern and Jetty-8 uses this approach for callbacks via our ForkInvoker class.
Jetty-9 IO Callbacks
For Jetty-9, we wanted the best of all worlds. We wanted to avoid deep re entrant stacks and to avoid dispatch delays. In a similar way to Servlet 3.1 WriteListeners, we wanted to substitute iteration for reentrancy when ever possible. Thus Jetty does not use NIO asynchronous IO channel APIs, but rather implements our own asynchronous IO pattern using the NIO Selector to implement our own EndPoint abstraction and a simple Callback interface:
public interface EndPoint extends Closeable { ... void write(Callback callback, ByteBuffer... buffers) throws WritePendingException; ... } public interface Callback { public void succeeded(); public void failed(Throwable x); }One key feature of this API is that it supports gather writes, so that there is less need for either iteration or re-entrancy when writing multiple buffers (eg headers, chunk and/or content). But other than that it is semantically the same as the NIO CompletionHandler and if used incorrectly could also suffer from deep stacks and/or dispatch latency.
Jetty Iterating Callback
Jetty’s technique to avoid deep stacks and/or dispatch latency is to use the IteratingCallback class as the basis of callbacks for tasks that may take multiple IO operations:
public abstract class IteratingCallback implements Callback { protected enum State { IDLE, SCHEDULED, ITERATING, SUCCEEDED, FAILED }; private final AtomicReference<State> _state = new AtomicReference<>(State.IDLE); abstract protected void completed(); abstract protected State process() throws Exception; public void iterate() { while(_state.compareAndSet(State.IDLE,State.ITERATING)) { State next = process(); switch (next) { case SUCCEEDED: if (!_state.compareAndSet(State.ITERATING,State.SUCCEEDED)) throw new IllegalStateException("state="+_state.get()); completed(); return; case SCHEDULED: if (_state.compareAndSet(State.ITERATING,State.SCHEDULED)) return; continue; ... } } public void succeeded() { loop: while(true) { switch(_state.get()) { case ITERATING: if (_state.compareAndSet(State.ITERATING,State.IDLE)) break loop; continue; case SCHEDULED: if (_state.compareAndSet(State.SCHEDULED,State.IDLE)) iterate(); break loop; ... } } }IteratingCallback is itself an example of another pattern used extensively in Jetty-9: it is a lock-free atomic state machine implemented with an AtomicReference to an Enum. This pattern allows very fast and efficient lock free thread safe code to be written, which is exactly what asynchronous IO needs.
The IteratingCallback class iterates on calling the abstract
process()method until such time as it returns the SUCCEEDED state to indicate that all operations are complete. If theprocess()method is not complete, it may return SCHEDULED to indicate that it has invoked an asynchronous operation (such asEndPoint.write(...)) and passed the IteratingCallback as the callback.Once scheduled, there are two possible outcomes for a successful operation. In the case that the operations completed trivially it will have called back
succeeded()within the scope of the write, thus the state will have been switched from ITERATING to IDLE so that the while loop in iterate will fail to set the SCHEDULED state and continue to switch from IDLE to ITERATING, thus callingprocess()again iteratively.In the case that the schedule operation does not complete within the scope of process, then the iterate while loop will succeed in setting the SCHEDULED state and break the loop. When the IO infrastructure subsequently dispatches a thread to callback
succeeded(), it will switch from SCHEDULED to IDLE state and itself call theiterate()method to continue to iterate on callingprocess().Iterating Callback Example
A simplified example of using an IteratingCallback to implement the AsyncWriter example from above is given below:
private class AsyncWriter extends IteratingCallback { private final Callback _callback; private final InputStream _in; private final EndPoint _endp; private final ByteBuffer _buffer; public AsyncWriter(InputStream in,EndPoint endp,Callback callback) { _callback=callback; _in=in; _endp=endp; _buffer = BufferUtil.allocate(4096); } protected State process() throws Exception { int l=_in.read(_buffer.array(), _buffer.arrayOffset(), _buffer.capacity()); if (l<0) { _callback.succeeded(); return State.SUCCEEDED; } _buffer.position(0); _buffer.limit(len); _endp.write(this,_buffer); return State.SCHEDULED; }Several production quality examples of IteratingCallbacks can be seen in the Jetty HttpOutput class, including a real example of asynchronously writing data from an input stream.
Conclusion
Jetty-9 has had a lot of effort put into using efficient lock free patterns to implement a high performance scalable IO layer that can be seamlessly extended all the way into the servlet application via the Servlet 3.1 asynchronous IO. Iterating callback and lock free state machines are just some of the advanced techniques Jetty is using to achieve excellent scalability results.
{kind=link}