Welcome to WordPress. This is your first post. Edit or delete it, then start writing!
Category: Uncategorized
-
If Virtual Threads are the solution, what is the problem?
Java’s Virtual Threads (aka Project Loom or JEP 444) have arrived as a full platform feature in Java 21, which has generated considerable interest and many projects (including Eclipse Jetty) are adding support.
I have previously been somewhat skeptical about how significant any advantages Virtual Threads actually have over Platform Threads (aka Native Threads). I’ve also pointed out that cheap Threads can do expensive things, so that using Virtual Threads may not be a universal panacea for concurrent programming.
However, even with those doubts, it is clear that Virtual Threads do have advantages in memory utilization and speed of startup. In this blog we look at what kinds of applications may benefit from those advantages.
In short we investigate what scalability problems are Virtual Threads the solution for.
Axioms
Firstly let’s agree on what is accepted about Virtual Thread usage:
- Writing asynchronous code is extraordinary difficult. “Yeah I know” you say… yeah but no, it is harder than that! Avoiding the need to write application logic in asynchronous style is key to improving the quality and stability of an application. This blog is not generally advocating you write your applications in an asynchronous style.
- Virtual Threads are very cheap to create. From a performance perspective there is no reason to pool already started Virtual Threads and such pools are considered an anti pattern. If a Virtual Thread is needed, then just create a new one.
- Virtual Threads use less memory. This is accepted, but with some significant caveats. Specifically the memory saving is achieved because Virtual Threads only allocate stack memory as needed, whilst Platform Threads provision stack size based on a worst case maximal usage. This is not exactly an apples vs oranges comparison.
If some are good, are more even better?
Consider a blocking style application is running on a traditional application server that is not scaling sufficiently. On inspection you see that all the Threads in the pool (default size 200) are allocated and that there are no Threads available to do more work!
Would making more Threads available be the solution to this scalability problem? Perhaps 2000 Platform Threads will help? Still slow? Let’s try 10,000 Platform Threads! Running out of memory? Then perhaps unlimited Virtual Threads will solve the scalability problems?
What if on further inspection it is found that the pool Threads are mostly blocked waiting for a JDBC Database connection from the JDBC Connection Pool (default size 8) and that as a result the Thread pool is exhausted.
If every request needs the database, then any additional Threads will all just block on the same JDBC pool, thus more Threads will not make a more Scalable solution.
Alternatively, if only some requests need to use the database, then having more Threads would allow request that do not need the database to proceed to completion. However, a fraction of requests would still end up blocked on the JBDC pool. Thus any limited Platform Thread pool could still become exhausted.
With unlimited Virtual Threads there is no effective limit on the number of Threads, so non database requests could always continue, but the queue of Threads waiting on JBDC would also be unlimited as would the total of any resources held by those Threads whilst waiting. Thus the application would only scale for some types of request, whilst giving JDBC dependent requests the same poor Quality of Service as before.
Finite Resources
If an application’s scalability is constrained by access to a finite resource, then it is unlikely that “more Threads” is the solution to any scalability problems. Just like you can’t solve traffic by adding cars to a congested road, adding Threads to an already busy server may make things worse.
Some common examples of finite resources that applications can encounter are:
- CPU: If the server CPU is near 100% utilization, then the existing number of Threads are sufficient to keep it fully loaded. More and/or faster CPUs are needed before any increase in Threads could be beneficial.
- Database: Many database technologies cannot handle many concurrent requests, so parallelism is restricted. If the bottleneck is the database, then it needs to be re-engineered rather than laid siege to by more concurrent Threads.
- Local Network: An application may block reading or writing data because it has reached the limit on the local network. In such cases, more Threads will not increase throughput, but they might improve latency if some threads can progress reading new requests and have responses ready to write once network becomes less congested. However there is a cost in waiting (see below).
- Locks: Parallel applications often use some form of lock or mutual exclusion to serialize access to common data structures. Contention on those locks can limit parallelism and require redesign rather than just more Threads.
- Caches: CPU, memory, file system and object caches are key tools in speeding up execution. However, if too many different tasks are executed concurrently, the capacity of these caches to hold relevant data may be exceeded and execution with a cold cache can be very slow. Sometimes it is better to do less things concurrently and serialize the excess so that caches can be more effective that trying to do everything at once.
If an application’s lack of scalability is due to Threads waiting for finite resources, then any additional Threads (Platform or Virtual) are unlikely to help and may make your application less stable. At best, careful redesign is needed before Thread counts can be increased in any advantageous way.
Infinite (OK Scalable) Resources
Not all resources are finite and some can be considered infinite, at least for some purposes. But let’s call them “Scalable” rather than infinite. Examples of scalable resources that an application may block on include:
- Database: Not all databases are created equal and some types of database have scalability in excess of the request rates experienced by a server. However, such scalability often comes at a latency cost as the database may be remote and/or distributed, thus applications may block waiting for the database, even if it has capacity to handle more requests in parallel.
- Micro services: A scalable database is really just a specific example of a micro service that may be provided by a remote and/or distributed system that has effectively infinite capacity at the cost of some latency. Applications can often find themselves waiting on one or more such services.
- Remote Networks: Local data center networks are often very VERY fast and in many situations they can outstrip even the combined capacity of many client systems. An application sending/receiving larger content may may block writing/reading them due to a slow client, but still have enough local network capacity to communicate with many other clients in parallel.
- Local Filesystems: Typically file systems are faster than networks, but slower than CPU. They also may have significant latency vs throughput tradeoffs (less so now that drives seldom need to spin physical disks). Thus Threads may block on local IO even though there is additional capacity available.
Applications that lack scalability due to Threads waiting for such scalable resources may benefit from more Threads. Whilst some Threads are waiting for the a database, micro service, slow client network or file system, it is likely that other Threads can progress even if they need to access the same types of resources.
Platform Threads pools can easily be increased to many 1000’s or more before typical servers will have memory issues. If scalability is needed beyond that, then Virtual Threads can offer practically unlimited additional Thread, but see the caveats below.
Furthermore, the fast starting Virtual Threads can be of significant benefit in situations where small jobs with long latency can be carried out in parallel. Consider an application that processes request using data from several micro services, each with some access latency. If these are done serially, then the total request latency is the summation of all. Sometimes asynchronous code is used to execute micro service request in parallel, but spinning up a couple of Virtual Threads in this situation is simpler, less error prone and applicable to more APIs.
Too Much of a Good Thing?
There is also some concern with low latency scalable resources that seldom block with Virtual Threads. Since Virtual Threads are not preempted, there can be starvation and/or fairness problems if they are not blocked by slow resources. This is probably a good problem to have, but will need some management on extreme scales for some applications.
The Cost of Waiting
We have identified that there are indeed scalable resources on which an application may wait with many Threads. However, there is no such thing as a free lunch and waiting Threads may have a significant cost, even if they are Virtual. Specifically how/where an application waits can greatly affect resource usage.
Consider a traditional application server with a limited Thread pool that is running near capacity, but with additional demand. While the 200 odd Threads are busy handling 200 concurrent request, there are additional request waiting to be handled. However, in an asynchronous server like Jetty, those additional requests can be cheaply parked and may be represented just be a single set bit in a selector or perhaps a tiny entry in a queue that holds only a reference to a connection that is ready to be read.
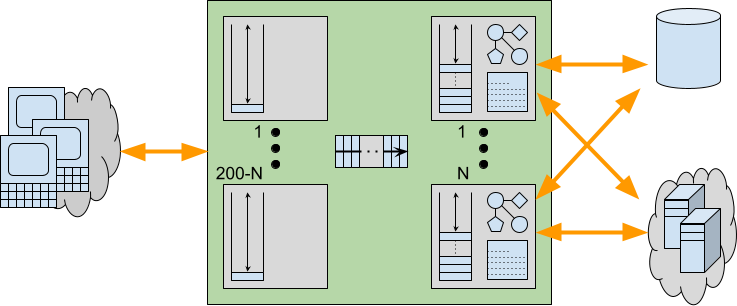
Now consider if requests were serviced by Virtual Threads instead of waiting for a pooled Platform Thread to become available. Pending requests would be allowed to proceed to some blocking point in the application. Waiting like this within the application can have additional expenses including:
- An input buffer will be allocated to read the request and any content it has.
- A read is performed into the input buffer, thus removing network back pressure so a client is enabled to send more request/data even if the server is unable to handle them.
- An object representation of the request will be built, containing at least the meta data and frequently some application data if there is an XML or JSON payload
- Sessions may be activated and brought into memory from caches or passivation stores.
- The allocated Thread runs deep inside the application code, potentially reaching near maximal stack depth.
- Application objects created on the heap are held in memory with references from the stack.
- An output buffer may be allocated, along with additional character conversion resources.
When request handling blocks within the application, all these additional resources may be allocated and held during that wait. Worse still, because of the lack of back pressure, a client may send more request/data resulting in more Threads and associated resources being allocated and also being held whilst the application waits for some resource.
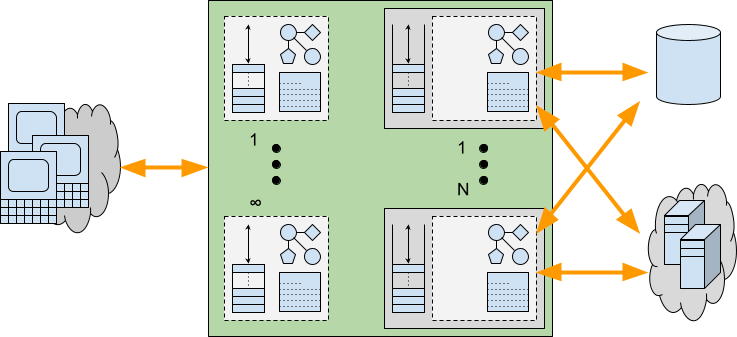
Provisioning for the Worst Case
We have seen that there are indeed applications that may benefit from having additional Threads available to service requests. But we have also seen that such additional Threads may incur additional costs beyond just the stack size. Waiting/Blocking within an application will typically be done with a deep stack and other resources allocated. Whilst Virtual Threads might be effectively infinite, it is unlikely that these other required resources are equally scalable.
When an application experiences a worst case peak in load, then ultimately some resource will run out. To provide good Quality of Service, it is vital that such resource exhaustion is handled gracefully, allowing some request handling to continue rather than suffering catastrophic failure.
With traditional Platform Thread based pools, stack memory is already provisioned for worst case stacks for all Threads and the thread pool sized limit is also an indirect limit on the number of concurrent resources used. Threads have sufficient resources available to complete there handling whilst any excess requests suffer latency whilst waiting cheaply for an available Thread. Furthermore, the back pressure resulting from not reading all offered requests can prevent additional load from sent by the clients. Thread limits are imperfect resource limits, but at least they are some kind of limit that can provide some graceful degradation under load.
Alternatively, an application using Virtual Threads that has no explicit resource management will be likely to exhaust some of the resources used by those Threads. This can result in an
OutOfMemoryExceptionor similar, as the unlimited Virtual Threads each allocate deep stacks and other resources needed for request handling. The cost of average memory savings may be insufficient provisioning for the worst case resulting in catastrophic failure rather than graceful degradation. An analogy is that building more roads can actually make traffic worse if the added cars overwhelm other infrastructure.Many applications are written without explicit resource limitations/management. Instead they rely on the imperfect Thread pool for at least some minimal protection. If that is removed, then some form of explicit resource limitation/management is likely to be needed in its place. Stable servers need to be provisioned for the worst case, not the average one.
Conclusion
There are applications that can scale better if more Threads are available, but it is not all applications (at least not without significant redesign). Consideration needs to be given to what will limit the worst case load for a server/application if it is not to be Threads. Specifically, the costs of waiting within the application may be such that scalability is likely to have a limit that will not be enforced by practically infinite Virtual Threads.
It may be that resources have limitations well within the capacity of large but limited Platform Thread pools, which are perfectly capable of scaling to many thousands of threads. So experiments with scaling a Platform Thread pool should first be used to see what limits do apply to an application.
If no upper limit is found before Platform Threads exhaust kernel memory, then Virtual Threads will allow scaling beyond that limit until some other limit is found. Thus the ultimate resource limit will need to be explicitly managed if catastrophic failure is to be avoided (but, to be fair, applications using Thread pools should also do some explicit resource limit management rather than rely just on the course limits of a Thread pool).
Recommendation
If Virtual Threads are not the general solution to scalability then what is? There is no one-size-fits-all solution, but I believe many applications that are limited by blocking on the network would benefit from being deployed in a server like Eclipse Jetty, that can do much of the handling for them asynchronously. Let Jetty read your requests asynchronously and prepare the content as parsed JSON, XML, or form data. Only then allocate a Thread (Virtual or Platform) with a large output buffer so the application can be written in blocking style, but will not block on either reading the request or writing the response. Finally, once the response is prepared, then let Jetty flush it to the network asynchronously. Jetty has always somewhat supported this model (e.g. by delaying dispatch to a Servlet until the first packet of data arrives), but with Jetty-12 we are adding more mechanisms to asynchronously prepare requests and flush responses, whilst leaving the application written in blocking style. More to come on this in future blogs!
-
Security Audit with Trail of Bits
Several months ago, the Eclipse Foundation approached the Eclipse Jetty project with the offer of a security audit. The effort was being supported through a collaboration with the Open Source Technology Improvement Fund (OSTIF), with the actual funding coming from the Alpha-Omega Project.
Upon reflection, this collaboration could not have come at a better time for the Jetty open-source project. Completing this security audit before the first release of Jetty 12 was serendipitous. While the collaboration results with Trail of Bits are just now being published, the work has primarily been completed for a couple of months.
When we started this audit effort, Jetty 12 was quickly shaping up to be one of the most exciting releases we have ever worked on in the history of Jetty. Support for protocols like HTTP/3 further refined the internals of Jetty to be a modern, scalable network component. Coupling that with a refactoring of the internals to remove strict dependency on Servlet Request and Response objects, the core of Jetty became a more general server component with scalable and performant applications being able to be developed directly in Jetty without the strict requirement for Servlets. This ultimately allowed us to add a new Environment concept that supports multiple versions of the Servlet API on the same Jetty server simultaneously; mixing javax.servlet and jakarta.servlet on the same server allows for many exciting options for our users.
However, these changes and exciting new features mean that quite a bit has changed, and when many moving parts are evolving, there is always a risk of unwanted behaviors.
Our committers had low expectations of what this engagement would lead to, as our previous experience with various code analysis tooling often resulted in too many false positives. Part of the prep work to start this review required us to draw an appropriate-sized box around the Jetty project code where we felt a review was most warranted. It should come as no surprise that much of this code is some of the more nuanced and complex with Jetty. So, throwing caution to the wind, we prepared and submitted the paperwork.
We could not have been more pleased with how the engagement proceeded from here. Trail of Bits was chosen as the company to perform the review, and it met and exceeded our expectations by far. Sitting down with their engineers, it was apparent they were excited to be working on an open-source project of Jetty’s maturity, and when their work was completed, they demonstrated a much more complete understanding of the reviewed code than the Jetty team expected.
Ultimately, we could not have been happier with how this effort was executed. The Eclipse Jetty project members are very thankful to the Eclipse Foundation, OSTIF, and Trail of Bits for making this collaboration a resounding success!
Other References
-
New Jetty 12 Maven Coordinates
Now that Jetty 12.0.1 is released to Maven Central, we’ve started to get a few questions about where some artifacts are, or when we intend to release them (as folks cannot find them).
Things have change with Jetty, starting with the 12.0.0 release.
First, is that our historical versioning of
<servlet_support>.<major>.<minor>is no longer being used.With Jetty 12, we are now using a more traditional
<major>.<minor>.<patch>versioning scheme for the first time.Also new in Jetty 12 is that the Servlet layer has been separated away from the Jetty Core layer.
The Servlet layer has been moved to the new Environments concept introduced with Jetty 12.
Environment Jakarta EE Servlet Jakarta Namespace Jetty GroupID ee8 EE8 4 javax.servletorg.eclipse.jetty.ee8ee9 EE9 5 jakarta.servletorg.eclipse.jetty.ee9ee10 EE10 6 jakarta.servletorg.eclipse.jetty.ee10Jetty Environments This means the old Servlet specific artifacts have been moved to environment specific locations both in terms of Java namespace and also their Maven Coordinates.
Example:
Jetty 11 – Using Servlet 5
Maven Coord:org.eclipse.jetty:jetty-servlet
Java Class:org.eclipse.jetty.servlet.ServletContextHandlerJetty 12 – Using Servlet 6
Maven Coord:org.eclipse.jetty.ee10:jetty-ee10-servlet
Java Class:org.eclipse.jetty.ee10.servlet.ServletContextHandlerWe have a migration document which lists all of the migrated locations from Jetty 11 to Jetty 12.
This new versioning and environment features built into Jetty means that new major versions of Jetty are not as common as they have been in the past.
-
Jetty Project and TCK
The Jetty project has a long history of participating in the standardization of EExx (previously JEE) specifications such as Servlet and Websocket.
Jakarta renaming
After the donation of TCK source code by Oracle to Eclipse Foundation, the EE group has decided to change the historical Java package names from javax.servlet or javax.websocket (etc..) to jakarta.servlet or jakarta.websocket (etc..). As we wanted to be able to validate our EE9 implementation, we have participated in the big change by contributing two Pull Requests doing the migration (Servlet/Websocket TCK https://github.com/jakartaee/platform-tck/pull/257) and (JSP, JSF, JAX* https://github.com/jakartaee/platform-tck/pull/276). Those Pull Requests have been a lot of work and testing as 1746 and 857 files of old/legacy code have been modified.
Refactoring of Servlet TCK
The original TCK (still the current main branch as of the date of writing) is based on a technology called JavaTest Harness (more details here). The problem with this technology is the slowness of test execution and the difficulties to debug what is happening.
After some discussion, a decision was made to rewrite All TCKs using Junit5 (or TestNG) and use Arquillian.
Starting with those requirements, it has been a long journey to refactor the Servlet TCK.
Originally, the Servlet TCK is a cascade of Ant builds which are packaging 210 war files to be deployed in the target Servlet container to be validated using the JavaTest Harness framework. This means a jvm is restarted 210 times to run all the tests and the TCK has 1691 tests.
On the Jetty CI, the daily build testing against the legacy TCK takes around 1h10min (Jenkins Job) and it’s not easy to set up such a run locally.
After the refactoring to use Arquillian and embedded Jetty instance, the similar Jenkins Job takes around 17 minutes (including a full rebuild of Arquillian Container Jetty, TCK servlet and Jetty 12).
Maven Build
As we were starting a big refactor with Jetty 12, having those 1691 tests was convenient to test all the changes but definitely too slow to run locally. So thus began the journey of rewriting the Servlet TCK.
The first job was to have a Maven build for the whole TCK, the branch called tckrefactor has been started to refactor the single source directory to multiple Maven modules with separation of concern. But as you can imagine this took some time to move Java files to the correct Maven modules without breaking some (circular?) dependencies that a single source directory was allowing.
Junit
Then we had to find the pattern (e.g. what do we have to do exactly?). As explained the TCK is/was a collection of wars and classes running using JavaTest Harness.
The tests were using the Javadoc taglet to discover the tests to be executed. The most complicated example is a mix using the Javadoc taglet such as:
public class Client extends secformClient { ...... /* * @testName: test1 * * @assertion_ids: Servlet:SPEC:142; JavaEE:SPEC:21 * * @test_Strategy: ..... * */ /* * @testName: test1_anno * * @assertion_ids: Servlet:SPEC:142; JavaEE:SPEC:21; Servlet:SPEC:290; * Servlet:SPEC:291; Servlet:SPEC:293; Servlet:SPEC:296; Servlet:SPEC:297; * Servlet:SPEC:298; * * @test_Strategy: ...... * */ public void test1_anno() throws Fault { // save off pageSec so that we can reuse it String tempPageSec = pageSec; pageSec = "/servlet_sec_secform_web/ServletSecAnnoTest"; try { super.test1(); } catch (Fault e) { throw e; } finally { // reset pageSec to orig value pageSec = tempPageSec; } }This test class when executed by the Java TestHarness framework will run
super.test1andtest1_annomethods. With moving to junit5 we need to add the annotation@Testto all methods which need to run.This means in this case we need to execute the
test1method in the superclass and the method test1_anno in the current class. The solution could be to mark test1_anno and the method test1 in the parent class with the annotation @Test but we cannot touch the parent class otherwise every class inheriting from this will this test method which is not expected and was not the behavior of the TestHarness framework.The solution is to mark it with @Test annotation the method test1_anno and modify the current source code to add the simple annotated method such as:
@Test public void test1() { super.test1(); }With more than 800 classes to touch this was not possible so we developed an Apache Maven plugin to achieve this: https://github.com/jetty-project/tck-extract-tests-maven-plugin
Arquillian
As mentioned above, the original TCK was based on Apache Ant building 212 war files to deploy. This means 212 Java files have to be modified to include the generation of the Arquillian WebArchive. Sadly nothing magical here as every build.xml was different and no way to find a pattern to automate this.
The solution was: Roll Up your sleeves™
Given a build.xml such as:
<property name="app.name" value="servlet_spec_errorpage" /> <property name="content.file" value="HTMLErrorPage.html"/> <property name="web.war.classes" value="com/sun/ts/tests/servlet/common/servlets/HttpTCKServlet.class, com/sun/ts/tests/servlet/common/util/Data.class"/> <target name="compile"> <ts.javac includes="${pkg.dir}/**/*.java, com/sun/ts/tests/common/webclient/validation/**/*.java, com/sun/ts/tests/servlet/common/servlets/**/*.java, com/sun/ts/tests/servlet/common/util/**/*.java"/> </target>was rewritten using Arquillian WebArchive generation in Java code (some manual checks had to be done as some
**/**/**were too “generous”) to:public static WebArchive getTestArchive() throws Exception { return ShrinkWrap.create(WebArchive.class, "servlet_spec_errorpage_web.war") .addAsWebResource("spec/errorpage/HTMLErrorPage.html","HTMLErrorPage.html") .addAsLibraries(CommonServlets.getCommonServletsArchive()) .addClasses(SecondServletErrorPage.class, ServletErrorPage.class, TestException.class, TestServlet.class, WrappedException.class) .setWebXML(URLClient.class.getResource("servlet_spec_errorpage_web.xml")); }This work has taken a lot of time and resources, and generated a quite big Pull Request: https://github.com/jakartaee/platform-tck/pull/912

With all of these changes, as long as your container has Arquillian support it’s very easy to run the Servlet TCK using Apache Maven Surefire with a configuration to pick up all the tests (a sample for Jetty is https://github.com/jetty-project/servlet-tck-run/blob/jetty-12-ee10/pom.xml).
Last but not least as the Jetty Arquilian container is embeded, it is now possible to debug everything (TCK code and Jetty code) using an IDE.
You can run even more TCK by adding them to the Apache Maven Surefire configuration:
<plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>${surefire.version}</version> <configuration> .... <includes> <include>**/URLClient*</include> <include>**/Client*</include> </includes> <excludes> <exclude>**/BaseUrlClient</exclude> </excludes> <dependenciesToScan> <dependenciesToScan>jakartatck:servlet</dependenciesToScan> </dependenciesToScan> </configuration> </plugin>The next steps are now to have other TCKs converted to Junit/Arquillian. Both Websocket, JSP and EL are works in progress.
-
Jetty & Log4j2 exploit CVE-2021-44228
The Apache Log4j2 library has suffered a series of critical security issues (see this page at the Log4j2 project).
Eclipse Jetty by default does not use and does not depend on Log4j2 and therefore Jetty is not vulnerable and thus there is no need for a Jetty release to address this CVE.
If you use Jetty embedded (i.e as a library in your application), and your application uses Log4j2, then you have to take the steps recommended by the CVE to mitigate possible impacts without worrying about the Jetty version.
However, Jetty standalone offers an optional Log4j2 Jetty module.
The following describes how you can test if your Jetty standalone configuration is using Log4j2, and how to upgrade to a fixed Log4j2 version without waiting for a release of Jetty.IMPORTANT: You must scan the content of your web applications deployed in Jetty, as they may contain a vulnerable Log4j2 artifact. Consult the CVE details to mitigate the vulnerability.
Eclipse Jetty 9
You can see your configuration of Jetty with a
--list-modulescommand in your$JETTY_BASEdirectory:$ java -jar $JETTY_HOME/start.jar --list-modules Enabled Modules: ================ 0) bytebufferpool transitive provider of bytebufferpool for server init template available with --add-to-start=bytebufferpool 1) log4j2-api transitive provider of log4j2-api for slf4j-log4j2 2) resources transitive provider of resources for log4j2-impl 3) log4j2-impl transitive provider of log4j2-impl for slf4j-log4j2 4) slf4j-api transitive provider of slf4j-api for slf4j-log4j2 5) slf4j-log4j2 transitive provider of slf4j-log4j2 for logging-log4j2 6) logging-log4j2 ${jetty.base}/start.d/logging-log4j2.ini 7) threadpool transitive provider of threadpool for server init template available with --add-to-start=threadpool 8) server ${jetty.base}/start.d/server.ini 9) http ${jetty.base}/start.d/http.iniHere you can see that the
logging-log4j2module is explicitly enabled and that it transitively depends onlog4j2-api.
The following command will show what version of the library is being used:$ java -jar $JETTY_HOME/start.jar --list-config Jetty Server Classpath: ----------------------- Version Information on 13 entries in the classpath. Note: order presented here is how they would appear on the classpath. changes to the --module=name command line options will be reflected here. 0: 2.14.0 | ${jetty.base}/lib/log4j2/log4j-api-2.14.0.jar 1: (dir) | ${jetty.base}/resources 2: 3.4.2 | ${jetty.base}/lib/log4j2/disruptor-3.4.2.jar 3: 2.14.0 | ${jetty.base}/lib/log4j2/log4j-core-2.14.0.jar 4: 2.14.0 | ${jetty.base}/lib/log4j2/log4j-slf4j-impl-2.14.0.jar 5: 1.7.32 | ${jetty.base}/lib/slf4j/slf4j-api-1.7.32.jar 6: 3.1.0 | ${jetty.home}/lib/servlet-api-3.1.jar 7: 3.1.0.M0 | ${jetty.home}/lib/jetty-schemas-3.1.jar 8: 9.4.44.v20210927 | ${jetty.home}/lib/jetty-http-9.4.44.v20210927.jar 9: 9.4.44.v20210927 | ${jetty.home}/lib/jetty-server-9.4.44.v20210927.jar 10: 9.4.44.v20210927 | ${jetty.home}/lib/jetty-xml-9.4.44.v20210927.jar 11: 9.4.44.v20210927 | ${jetty.home}/lib/jetty-util-9.4.44.v20210927.jar 12: 9.4.44.v20210927 | ${jetty.home}/lib/jetty-io-9.4.44.v20210927.jarHere we can see that the vulnerable Log4j2
2.14.0version is being used.
The following commands will remove that jar and update the Jetty base to use the fixed Log4j22.17.0jar:$ echo 'log4j2.version=2.17.0' >> start.d/logging-log4j2.ini $ rm -f lib/log4j2/* $ java -jar $JETTY_HOME/start.jar --create-files $ java -jar $JETTY_HOME/start.jar --list-config Jetty Server Classpath: ----------------------- Version Information on 13 entries in the classpath. Note: order presented here is how they would appear on the classpath. changes to the --module=name command line options will be reflected here. 0: 2.17.0 | ${jetty.base}/lib/log4j2/log4j-api-2.17.0.jar 1: (dir) | ${jetty.base}/resources 2: 3.4.2 | ${jetty.base}/lib/log4j2/disruptor-3.4.2.jar 3: 2.17.0 | ${jetty.base}/lib/log4j2/log4j-core-2.17.0.jar 4: 2.17.0 | ${jetty.base}/lib/log4j2/log4j-slf4j-impl-2.17.0.jar 5: 1.7.32 | ${jetty.base}/lib/slf4j/slf4j-api-1.7.32.jar 6: 3.1.0 | ${jetty.home}/lib/servlet-api-3.1.jar 7: 3.1.0.M0 | ${jetty.home}/lib/jetty-schemas-3.1.jar 8: 9.4.44.v20210927 | ${jetty.home}/lib/jetty-http-9.4.44.v20210927.jar 9: 9.4.44.v20210927 | ${jetty.home}/lib/jetty-server-9.4.44.v20210927.jar 10: 9.4.44.v20210927 | ${jetty.home}/lib/jetty-xml-9.4.44.v20210927.jar 11: 9.4.44.v20210927 | ${jetty.home}/lib/jetty-util-9.4.44.v20210927.jar 12: 9.4.44.v20210927 | ${jetty.home}/lib/jetty-io-9.4.44.v20210927.jarEclipse Jetty 10 & 11
You can see your configuration of Jetty with a
--list-modulescommand in your$JETTY_BASEdirectory:$ java -jar $JETTY_HOME/start.jar --list-modules Enabled Modules: ---------------- 0) resources transitive provider of resources for logging-log4j2 1) logging/slf4j dynamic dependency of logging-log4j2 transitive provider of logging/slf4j for logging-log4j2 2) logging-log4j2 ${jetty.base}/start.d/logging-log4j2.ini 3) bytebufferpool transitive provider of bytebufferpool for server init template available with --add-module=bytebufferpool 4) threadpool transitive provider of threadpool for server init template available with --add-module=threadpool 5) server transitive provider of server for http init template available with --add-module=server 6) http ${jetty.base}/start.d/http.iniHere you can see that the
logging-log4j2module is explicitly enabled and that it transitively depends onlog4j2-api. The following command will show what version of the library is being used:$ java -jar $JETTY_HOME/start.jar --list-config Properties: ----------- java.version = 14.0.2 java.version.major = 14 java.version.micro = 2 java.version.minor = 0 java.version.platform = 14 jetty.base = /tmp/test jetty.base.uri = file:///tmp/test jetty.home = /opt/jetty-home-11.0.7 jetty.home.uri = file:///opt/jetty-home-11.0.7 jetty.webapp.addServerClasses = org.apache.logging.log4j.,org.slf4j. log4j.version = 2.14.1 runtime.feature.alpn = true slf4j.version = 2.0.0-alpha5
Here we can see that the vulnerable Log4j2
2.14.1version is being used.
The following commands will remove that jar and update the Jetty base to use the fixed Log4j22.17.0jar:$ echo 'log4j.version=2.17.0' >> start.d/logging-log4j2.ini $ rm -f lib/logging/* $ java -jar $JETTY_HOME/start.jar --create-files $ java -jar $JETTY_HOME/start.jar --list-config
Properties: ----------- java.version = 14.0.2 java.version.major = 14 java.version.micro = 2 java.version.minor = 0 java.version.platform = 14 jetty.base = /tmp/test jetty.base.uri = file:///tmp/test jetty.home = /opt/jetty-home-11.0.7 jetty.home.uri = file:///opt/jetty-home-11.0.7 jetty.webapp.addServerClasses = org.apache.logging.log4j.,org.slf4j. log4j.version = 2.17.0 runtime.feature.alpn = true slf4j.version = 2.0.0-alpha5 Jetty Server Classpath: ----------------------- Version Information on 11 entries in the classpath. Note: order presented here is how they would appear on the classpath. changes to the --module=name command line options will be reflected here. 0: (dir) | ${jetty.base}/resources 1: 2.0.0-alpha5 | ${jetty.home}/lib/logging/slf4j-api-2.0.0-alpha5.jar 2: 2.17.0 | ${jetty.base}/lib/logging/log4j-slf4j18-impl-2.17.0.jar 3: 2.17.0 | ${jetty.base}/lib/logging/log4j-api-2.17.0.jar 4: 2.17.0 | ${jetty.base}/lib/logging/log4j-core-2.17.0.jar 5: 5.0.2 | ${jetty.home}/lib/jetty-jakarta-servlet-api-5.0.2.jar 6: 11.0.7 | ${jetty.home}/lib/jetty-http-11.0.7.jar 7: 11.0.7 | ${jetty.home}/lib/jetty-server-11.0.7.jar 8: 11.0.7 | ${jetty.home}/lib/jetty-xml-11.0.7.jar 9: 11.0.7 | ${jetty.home}/lib/jetty-util-11.0.7.jar 10: 11.0.7 | ${jetty.home}/lib/jetty-io-11.0.7.jarConclusions
It is recommended that you update any usage of Log4j2 immediately.
Once you upgrade your version of Jetty, you will need to edit the
start.d/logging-log4j2.inifile to remove the explicit setting of the Log4j2 version, so that you may use newer Log4j2 versions. -
Community Projects & Contributors Take on Jakarta EE 9
With the recent release of JakartaEE9, the future for Java has never been brighter. In addition to headline projects moving forward into the new jakarta.* namespace, there has been a tremendous amount of work done throughout the community to stay at the forefront of the changing landscape. These efforts are the summation of hundreds of hours by just as many developers and highlight the vibrant ecosystem in the Jakarta workspace.
The Jakarta EE contributors and committers came together to shape the 9 release. They chose to create a reality that benefits the entire Jakarta EE ecosystem. Sometimes, we tend to underestimate our influence and the power of our actions. Now that open source is the path of Jakarta EE, you, me, all of us can control the outcome of this technology.
Such examples that are worthy of emulation include the following efforts. In their own words:Eclipse Jetty – The Jetty project recently released Jetty 11, which has worked towards full compatibility with JakartaEE9 (Servlet, JSP, and WebSocket). We are driven by a mission statement of “By Developers, For Developers”, and the Jetty team has worked since the announcement of the so-called “Big Bang” approach to move Jetty entirely into the jakarta.* namespace. Not only did this position Jetty as a platform for other developers to push their products into the future, but also allowed the project to quickly adapt to innovations that are sure to come.
[Michael Redich] The Road to Jakarta EE 9, an InfoQ news piece, was published this past October to highlight the efforts by Kevin Sutter, Jakarta EE 9 Release Lead at IBM, and to describe the progress made this past year in making this new release a reality. The Java community should be proud of their contributions to Jakarta EE 9, especially implementing the “big bang,” and discussions have already started for Jakarta EE 9.1 and Jakarta EE 10. The Q&A with Kevin Sutter in the news piece includes the certification and voting process for all the Jakarta EE specifications, plans for upcoming releases of Jakarta EE, and how Java developers can get involved in contributing to Jakarta EE. Personally, I am happy to have been involved in Jakarta EE having authored 14 Jakarta EE-related InfoQ news items for the three years, and I look forward to taking my Jakarta EE contributions to the next level. I have committed to contributing to the Jakarta NoSQL specification which is currently under development. The Garden State Java User Group (in which I serve as one of its directors) has also adopted Jakarta NoSQL. I challenge anyone who still thinks that the Java programming language is dead because these past few years have been an exciting time to be part of this amazing Java community!
WildFly 22 Beta1 contains a tech preview EE 9 variant called WildFly Preview that you can download from the WildFly download page. The WildFly team is still working on passing the needed (Jakarta EE 9) TCKs (watch for updates via the wildfly.org site.) WildFly Preview includes a mix of native EE 9 APIs and implementations (i.e. ones that use the jakarta.* namespace) along with many APIs and implementations from EE 8 (i.e. ones that use the java.* namespace). This mix of namespaces is made possible by using the Eclipse community’s excellent Eclipse Transformer project to bytecode transformer legacy EE 8 artifacts to EE 9 when the server is provisioned. Applications that are written for EE 8 can also run on WildFly Preview, as a similar transformation is performed on any deployments managed by the server.
Apache TomEE is a Jakarta EE application server based on Apache Tomcat. The project main focus is the Web Profile up until Jakarta EE 8. However, with Jakarta EE 9 and some parts being optional or pruned, the project is considering the full platform for the future. TomEE is so far a couple of tests down (99% coverage) before it reaches compatibility with Jakarta EE 8 (See Introducing TCK Work and how it helps the community jump into the effort). For Jakarta EE 9, the Community decided to pick a slightly different path than other implementations. We have already produced a couple of Apache TomEE 9 milestones for Jakarta EE 9 based on a customised version of the Eclipse Transformer. It fully supports the new jakarta.* namespace. Not to forget, the project also implements MicroProfile.
Open Liberty is in the process of completing a Compatible Implementation for Jakarta EE 9. For several months, the Jakarta EE 9 implementation has been rolling out via the “monthly” Betas. Both of the Platform and Web Profile TCK testing efforts are progressing very well with 99% success rates. The expectation is to declare one (or more) of the early Open Liberty 2021 Betas as a Jakarta EE 9 Compatible Implementation. Due to Open Liberty’s flexible architecture and “zero migration” goal, customers can be assured that their current Java EE 7, Java EE 8, and Jakarta EE 8 applications will continue to execute without any changes required to the application code or server configuration. But, with a simple change to their server configuration, customers can easily start experimenting with the new “jakarta” namespace in Jakarta EE 9.
Jelastic PaaS is the first cloud platform that has already made Jakarta EE 9 release available for the customers across a wide network of distributed hosting service providers. For the last several months Jelastic team has been actively integrating Jakarta EE 9 within the cloud platform and in December made an official release. The certified container images with the following software stacks are already updated and available for customers across over 100 data centers: Tomcat, TomEE, GlassFish, WildFly and Jetty. Jelastic PaaS provides an easy way to create environments with new Jakarta EE 9 application servers for deep testing, compatibility checks and running live production environments. It’s also possible now to redeploy existing containers with old versions to the newest ones in order to reduce the necessary migration efforts, and to expedite adoption of cutting-edge cloud native tools and products.
[Amelia Eiras] Pull Request 923- Jakarta EE 9 Contributors Card is a formidable example of eleven-Jakartees coming together to create, innovate and collaborate on an Integration-Feature that makes it so that no contributor, who helped on Jakarta EE 9 release, be forgotten in the new landing page for the EE 9 Release. Who chose those Contributors? None. That is the sole point of the existence of PR923.I chose to lead the work on the PR and worked openly by prompt communications delivered the day that Tomitribe submitted the PR – Jakarta EE Working Group message to the forum to invite other Jakartees to provide input in the creation of the new feature. With Triber Andrii, who wrote the code and the feedback of those involved, the feature is active and used in the EE 9 contributors cards, YOU ROCK WALL!
The Integration-Feature will be used in future releases. We hope that it is also adopted by any project, community, or individual in or outside the Eclipse Foundation to say ThankYOU with actions to those who help power & maintain any community.- PR logistics: 11 Jakartees came together and produced 116 exchanges that helped merge the code. Thank you, Chris (Eclipse WebMaster) for helping check the side of INFRA. The PR’s exchanges lead us to choose the activity from 2 GitHub sources: 1) https://github.com/jakartaee/specifications/pulls all merged pulls and 2) https://github.com/eclipse-ee4j all repositories.
- PR Timeframe: the Contributors’ work accomplished from October 31st, 2019 to November 20th, 2020, was boxed and is frozen. The result is that the Contributor Cards highlight 6 different Jakartees at a time every 15 seconds. A total of 171 Jakartee Contributors (committers and contributors, leveled) belong to the amazing people behind EE 9 code. While working on that PR, other necessary improvements become obvious. A good example is the visual tweaks PR #952 we submitted that improved the landing page’s formatting, cards’ visual, etc.
Via actions, we chose to not “wait & see”, saving the project $budget, but also enabling openness to tackle the stuff that could have been dropped into “nonsense”.
In open-source, our actions project a temporary part of ourselves, with no exceptions. Those actions affect positively or negatively any ecosystem. Thank you for taking the time to read this #SharingIsCaring blog.
-
Jetty 10 and 11 Have Arrived!
The Eclipse Jetty team is proud to announce the release of Jetty 10 and Jetty 11! Let’s first get into the details of Jetty 10, which includes a huge amount of enhancements and upgrades. A summary of the changes follows.
Minimum Java Version
The minimum required Java version for Jetty 10 is now Java 11.
As new versions of the OpenJDK are released, Jetty is tested for compatibility and is at this point compatible with versions up to Java 15.WebSocket Refactor
- Major refactor of Jetty WebSocket code. The Jetty WebSocket core API now provides the RFC6455 protocol implementation. The Jetty and Javax WebSocket APIs are separate layers which use the new WebSocket core implementation.
- Support for RFC8441 WebSocket over HTTP/2 on both WebSocket client and WebSocket server. This allows a HTTP/2 stream to be upgraded to a WebSocket connection allowing the single TCP connection to be shared by both HTTP/2 and WebSocket protocols.
- Various improvements and cleanups to the Jetty WebSocket API.
Self Ordering Webapp Configurations.
- The new WebAppContext Configuration API, useful for embedded Jetty users, have been made simpler to use.
- The available Configurations are discovered with the ServiceLoader, so that often all that is required is to add a feature jar onto the server classpath for that feature to be applied to all web applications.
- Configurations are self ordering using before/after dependencies defined in the Configurations themselves. This removes the need to explicitly order Configurations or to use add-after style semantics.
- A Configuration now includes the ability to condition the Webapp classloader so that classes/packages on the server class loader can be explicitly hidden, protected and/or exposed to the Webapp classloader.
HTTP Session Refactor
The HTTP session storage integrations were refactored to be consistent. Previously, the various integrations discovered expired sessions in different ways and with different thresholds for expiry. The refactoring applies the same uniform criteria for expiry no matter the persistence technology used. Some of the configuration properties have changed as a result of the refactoring.
New XML DTD
The Jetty XML files now validate against the new configure_10_0.dtd. We encourage moving to the new DTD.
Jetty Distribution Change
There is no longer a jetty-distribution artifact, use the equivalent jetty-home artifact.
The $JETTY_BASE mechanism has not changed. Upgrades should be mostly transparent, only custom XML in your $JETTY_BASE and logging require migration.Jetty-Quickstart Just Got Easier to Use
In Jetty 10 it is easier to use the jetty-quickstart mechanism to improve the start-up time of webapps. Previously it was necessary to enable the quickstart module and also create a special context xml file for your webapp and explicitly apply some configuration. With Jetty 10 you no longer need the special context xml file: you simply enable the quickstart module, and then edit the generated start.d/quickstart.ini file to either force generation or use a pre-generated quickstart file.
Expanded JPMS Support
Jetty 10 is now fully JPMS compliant with proper JPMS modules and module-info.class files, improving over Jetty 9.4.x where only the Automatic-Module-Name was defined for each artifact.
This allows other libraries to leverage Jetty JPMS modules properly, and use jlink to create custom images that embed Jetty.HTTP Client
HttpClient has undergone a number of changes, in particular:
- An improved API for setting request and response headers, based on the new HttpFields and HttpField.Mutable APIs.
- An improved API for setting request content, based on a reactive model where the demand of content and buffer recycling can now be performed separately. This allows applications to provide request content implementations in a much simpler way, without the need to know HttpClient implementation details.
- The introduction of ClientConnector, a reusable component that manages the connections opened by HttpClient that can now be shared with HTTP2Client, and that centralizes the configuration of other components such as the Executor, the Scheduler, the SslContextFactory, and the TCP properties.
- The introduction of a dynamic HttpClientTransport that allows switching, for example, from HTTP/1.1 to HTTP/2 after negotiation with the server. This allows us to write web spiders or proxies that can prefer HTTP/2 but fall back to HTTP/1.1 if the server does not support HTTP/2.
- Support for tunneling WebSocket over HTTP/2 (this feature is primarily used by the WebSocketClient – for the application it should be transparent)
- Support for the PROXY protocol so that proxy applications that use HttpClient can use the PROXY protocol and forward client TCP data (and metadata when using PROXY v2) to the server.
Logging
Jetty 9 and earlier had its own Logging Facade.
Starting with Jetty 10, that custom facade has been completely replaced by SLF4J 2.0 API usage. You can use any logging implementation you want with Jetty, as long as there is an SLF4J 2.x implementation available for it.
The entire org.eclipse.jetty.util.log package has seen large changes in Jetty 10.- org.eclipse.jetty.util.log.Log is deprecated and all methods just delegate to SLF4J.
- org.eclipse.jetty.util.log.Logger is deprecated and is not used.
- No other classes from Jetty 9 exist in this package.
In Jetty 10, there is also a new optional SLF4J implementation provided by Jetty in the form of (jetty-slf4j-impl) which performs the same functionality as the old StdErrLog from Jetty 9 and earlier, with support for configuring logging levels via the jetty-logging.properties classpath resource.
The format of the jetty-logging.properties file is almost identical to what it was before.
The following properties have been removed (and cause no changes in the configuration and no warnings or errors in Jetty 10 forward)- org.eclipse.jetty.util.log.class=<classname>
- This has no property replacement, correct SLF4J jar file usage is how you configure this.
- org.eclipse.jetty.util.log.IGNORED=<boolean>
- There is no replacement for “IGNORED” logging level.
- org.eclipse.jetty.util.log.announce=<boolean>
- Logging announcement is not a feature of Jetty but could be part of the logging implementation you choose, configuring this would be in the logging implementation you choose.
- org.eclipse.jetty.util.log.SOURCE=<boolean>
- org.eclipse.jetty.util.log.stderr.SOURCE=<boolean>
- Source logging is a possible feature of the specific SLF4J implementation you choose, check their documentation.
There are new properties as well:
- org.eclipse.jetty.logging.appender.NAME_CONDENSE=<boolean>
- This was the old org.eclipse.jetty.util.log.stderr.LONG which controlled the output of the logger name. (true means the package name are condensed in the output, false means the fully qualified class name is used in output) – defaults to true
- org.eclipse.jetty.logging.appender.THREAD_PADDING=<int>
- This was the old org.eclipse.jetty.util.log.StdErrLog.TAG_PAD for aligning all messages to a common offset from the start of the log line. – defaults to -1
- org.eclipse.jetty.logging.appender.MESSAGE_ESCAPE=<boolean>
- This was the old org.eclipse.jetty.util.log.stderr.ESCAPE for turning on/off the escaping of control characters found in the message text. – defaults to true
- org.eclipse.jetty.logging.appender.ZONE_ID=<timezone-id>
- This defaults to java.util.TimeZone.getDefault() and is present to allow setting the output timestamp in the desired timezone.
Jetty 11
When Oracle donated the JavaEE project to the Eclipse foundation, they maintained the copyright to the javax.* namespace. Subsequently, future versions of JavaEE, now called JakartaEE, would be required to use a new namespace for those packages. Instead of an incremental process, the Eclipse foundation opted for a big bang approach and packages formerly under the javax.* namespace has been refactored under the new jakarta.* namespace.
Enter Jetty 11. Jetty 11 is identical to Jetty 10 except that the javax.* packages now conform to the new jakarta.* namespace. Jetty 10 and 11 will remain in lockstep with each other for releases, meaning all new features or bug fixes in one version will be available in the other.
It is important to note that Jetty 10.x will be the last major Jetty version to support the javax.* namespace. If this is alarming, be assured that Jetty 10 will be supported for a number of years to come. We have no plans on releasing it only to drop support for it in 12-18 months. -
Renaming Jetty from javax.* to jakarta.*
The Issue
The Eclipse Jakarta EE project has not obtained the rights from Oracle to extend the Java EE APIs living in the
javax.*package. As such, the Java community is faced with a choice between continuing to use the frozenjavax.*APIs or transitioning to a newjakarta.*namespace where these specifications could continue to be evolved and/or significantly changed.
This name change is now a “fait accompli” (a.k.a. “done deal”), so it will happen no matter what. However, how the Eclipse Jakarta EE specification process handles the transition and how vendors like Webtide respond are yet to be determined.
This blog discusses some of the options for how Webtide can evolve the Jetty project to deal with this renaming.Jakarta EE Roadmap
Jakarta EE 8
A release of Jakarta EE 8 will happen first, and that will include:
- An update to Licensing
- An update to Naming (to limit the use of the trademarked term “Java”)
- An update to the Maven GroupID Coordinate Space in Maven Central
- No change to the Java packaging of the old Java EE 8 classes; they still retain their
javax.*namespace.
For example, the current Maven coordinates for the Servlet jar are (
groupId:artifactId:version):
javax.servlet:javax.servlet-api:4.0.1
With Jakarta EE 8, these coordinates will change to:
jakarta.servlet:jakarta.servlet-api:4.0.2
The content of these 2 jars will be identical: both will containjavax.servlet.Servlet.Jakarta EE 9
The Eclipse Jakarta EE project is currently having a debate about what the future of Jakarta looks like. Options include:
Jakarta EE “Big Bang” Rename Option
Jakarta EE 9 would rename every API and implementation to use the
jakarta.*namespace API.
This means thatjavax.servlet.Servletwill becomejakarta.servlet.Servlet.
No other significant changes would be made (including not removing any deprecated methods or behaviours). This requires applications to update the package imports fromjavax.*tojakarta.*en mass to update possible dependencies to versions that use thejakarta.*APIs (e.g. REST frameworks, etc.) and recompile the application.
Alternatively, backward compatibility would be required (provided by Containers) in some form so that legacyjavax.*code could be deployed (at least initially) with static and/or dynamic translation and/or adaption.
For example, Container vendors could provide tools that pre-process yourjavax.*application, transforming it into ajakarta.*application. Exact details of how these tools will work (or even exist) are still uncertain.Jakarta EE Incremental Change
Jakarta EE 9 would maintain any
javax.*API that did not require any changes. Only those APIs that have been modified/updated/evolved/replaced would be in thejakarta.*namespace.
For example, if the Servlet 4.0 Specification is not updated, it will remain in thejavax.*package.
However, if the Servlet Specification leaders decide to produce a Servlet 5.0 Specification, it will be in thejakarta.* package.
The Current State of Servlet Development
So far, there appears very little user demand for iterations on the Servlet API.
The current stable Jetty release series, 9.4.x, is on Servlet 3.1, which has not changed since 2013.
Even though Servlet 4.0 was released in 2017, we have yet to finalize our Jetty 10 release using it, in part waiting for new eclipse Jakarta artifacts for the various EE specs, eg: servlet-api, jsp-api, el-api, websocket-api, and mail-api. Despite being 2 years late with Servlet 4.0, we have not received a single user request asking for Servlet 4.0 features or a release date.
On the other hand, there has been interest from our users in more significant changes, some of which we have already started supporting in Jetty specific APIs:- JPMS integration/support
- Asynchronously filter input/output streams without request/response wrapping
- Reactive style asynchronous I/O
- Minimal startup times (avoiding discovery mechanisms) to facilitate fast spin-up of new cloud instances
- Micro deployments of web functions
- Asynchronous/background consumption of complex request content: XML, JSON, form parameters, multipart uploads etc.
Jetty Roadmap
Jetty 10
Jetty 10, implementing the Servlet 4.0 Specification, will be released once the frozen Jakarta EE 8 artifacts are available. These artifacts will have a Maven groupId of
jakarta.*, but will contain classes in thejavax.*packages.
It is envisioned that Jetty 10 will soon after become our primary stable release of Jetty and will be enhanced for several years and maintained for many more. In the mid-term, it is not Webtide’s intention to force any user to migrate to the newjakarta.*APIs purely due to the lack of availability of ajavax.*implementation. Any innovations or developments done in Jetty 10 will have to be non standard extensions.
However, we are unable to commit to long term support for the external dependencies bundled with a Jetty release that use thejavax.*package (eg. JSP, JSTL, JNDI, etc.) unless we receive such commitments from their developers.Jetty 11
Jetty 11 would be our first release that uses the Jakarta EE 9 APIs. These artifacts will have a Maven groupId of
jakarta.*and contain classes also in thejakarta.*packages.
We are currently evaluating if we will simply do a rename (aka Big Bang) or instead take the opportunity to evolve the server to be able to run independently of the EE APIs and thus be able to support bothjavax.*andjakarta.*Jetty Options with Jakarta EE “Big Bang”
If the Eclipse foundation determines that the existing
javax.*APIs are to be renamed tojakarta.*APIs at once and evolved, then the following options are available for the development of future Jetty versions.
Note that current discussions around this approach will not change anything about the functionality present in the existing APIs (eg: no removal of deprecated methods or functions. no cleanup or removal of legacy behaviors. no new functionality, etc)Option 0. Do Nothing
We keep developing Jetty against the
javax.*APIs which become frozen in time.
We would continue to add new features but via Jetty specific APIs. The resources that would have otherwise been used supporting the rename tojakarta.*will be used to improve and enhance Jetty instead.
For users wishing to stay withjavax.*this is what we plan to do with Jetty 10 for many years, so “Do Nothing” will be an option for some time. That said, if Jetty is to continue to be a standards-based container, then we do need to explore additional options.Option 1. “Big Bang” Static Rename
Jetty 11 would be created by branching Jetty 10 and renaming all
javax.*code to usejakarta.*APIs from Jakarta EE9. Any users wishing to runjavax.*code would need to do so on a separate instance of Jetty 10 as Jetty 11 would only run the new APIs.
New features implemented in future releases of Jakarta EE APIs would only be available in Jetty 11 or beyond. Users that wish to use the latest Jetty would have to do the same rename in their entire code base and in all their dependencies.
The transition to the new namespace would be disruptive but is largely a one-time effort. However, significant new features in the APIs would be delayed by the transition and then constrained by the need to start from the existing APIs.Option 2. “Big Bang” Static Rename with Binary Compatibility
This option is essentially the same as Option 1, except that Jetty 11 would include tools/features to dynamically rename (or adapt – the technical details to be determined)
javax.*code usage, either as it is deployed or via pre-deployment tooling. This would allow existing code to run on the new Jetty 11 releases. However, as the Jakarta APIs evolve, there is no guarantee that this could continue to be done, at least not without some runtime cost. The Jakarta EE project is currently discussing backward compatibility modes and how (or if) these will be specified.
This approach minimizes the initial impact of transitioning, as it allows legacy code to continue to be deployed. The downside, however, is that these impacts may be experienced for many years until that legacy code is refactored. These effects will include the lost opportunities for new features to be developed as development resources are consumed implementing and maintaining the binary compatibility feature.Option 3. Core Jetty
We could take the opportunity forced on us by the renaming to make the core of Jetty 11 independent of any Jakarta EE APIs.
A new modern lightweight core Jetty server would be developed, based on the best parts of Jetty 10, but taking the opportunity to update, remove legacy concerns, implement current best practices and support new features.
Users could develop to this core API as they do now for embedded Jetty usage. Current embedded Jetty code would need to be ported to the new API (as it would with anyjavax.*rename tojakarta.*).
Standard-based deployments would be supported by adaption layers providing the servlet container and implementations would be provided for bothjavax.*andjakarta.*. A single server would be able to run both old and new APIs, but within a single context, the APIs would not be able to be mixed.
This is a significant undertaking for the Jetty Project but potentially has the greatest reward as we will obtain new features, not just a rename.Jetty Options with Jakarta EE Incremental Change
These are options if the Eclipse foundation determines that the
jakarta.*package will be used only for new or enhanced APIs.Option 4. Jakarta Jetty
This option is conceptually similar to Option 3, except that the new Jetty core API will be standardized by Jakarta EE 9 (which will hopefully be a lightweight core) to current best practices and include new features.
Users could develop to this new standard API. Legacy deployments would be supported by adaption layers providing thejavax.*servlet container, which may also be able to see new APIs and thus mix development.Option 5. Core Jetty
This option is substantially the same as Option 3 as Jetty 11 would be based around an independent lightweight core API.
Users could develop to this core API as they do now for embedded Jetty usage. Standard-based deployments would be supported by adaption layers providing the servlet container and implementations would be provided for bothjavax.*andjakarta.*.How You Can Get Involved
As with any large-scale change, community feedback is paramount. We invite all users of Jetty, regardless of how you consume it, to make your voice heard on this issue.
For Jetty-specific feedback, we have opened messages on both thejetty-usersandjetty-devmailing lists. These discussions can be found below:
https://www.eclipse.org/lists/jetty-users/msg08908.html
https://www.eclipse.org/lists/jetty-dev/msg03307.html
To provide feedback on the broader change from thejavax.*tojakarta.*namespace, you can find a discussion on the jakartaee-platform-dev mailing list:
https://www.eclipse.org/lists/jakartaee-platform-dev/msg00029.html -
Indexing/Listing Vulnerability in Jetty
If you are using DefaultServlet or ResourceHandler with indexing/listing, then you are vulnerable to a variant of XSS behaviors surrounding the use of injected HTML element attributes on the parent directory link. We recommend disabling indexing/listing or upgrading to a non-vulnerable version.
To disable indexing/listing:
If using the DefaultServlet (provided by default on a standard WebApp/WAR), you’ll set the dirAllowed init-param to false.
This can be controlled in a few different ways:
Directly in your WEB-INF/web.xml
Add/edit the following entry …<servlet> <servlet-name>default</servlet-name> <servlet-class>org.eclipse.jetty.servlet.DefaultServlet</servlet-class> <init-param> <param-name>dirAllowed</param-name> <param-value>false</param-value> </init-param> ... (other init) ... <load-on-startup>0</load-on-startup> </servlet>Alternatively, you’ll edit your configured web descriptor default (usually declared as webdefault.xml) or your web descriptor override-web.xml.
The web defaults descriptor can either be configured at the WebAppProvider level and will be applied to all webapps being deployed, or at the individual webapp.
For the WebAppProvider level, you have several choices.
If you are managing the XML yourself, you can set the Default Descriptor to your edited version:<Call id="webappprovider" name="addAppProvider"> <Arg> <New class="org.eclipse.jetty.deploy.providers.WebAppProvider"> <Set name="monitoredDirName"> <Property name="jetty.base"/>/other-webapps </Set> <Set name="defaultsDescriptor"> <Property name="jetty.base"/>/etc/webdefault.xml </Set> <Set name="extractWars">true</Set> <Set name="configurationManager"> <New class="org.eclipse.jetty.deploy.PropertiesConfigurationManager"/> </Set> </New> </Arg> </Call>Note: the WebAppProvider cannot set the override-web.xml for all webapps.
If you are using the jetty.home/jetty.base module system and associated start.d/*.ini or start.ini, then you should be able to just point to your specifically edited webdefault.xml.
Example:$ grep jetty.deploy.defaultsDescriptorPath start.d/depoy.ini jetty.deploy.defaultsDescriptorPath=/path/to/fixed/webdefault.xml
If you are using a webapp specific deployment XML, such as what’s found in ${jetty.base}/webapps/<appname>.xml then you’ll edit the XML to point to your specific webdefault.xml or override-web.xml:
<Configure id="exampleWebapp" class="org.eclipse.jetty.webapp.WebAppContext"> <Set name="contextPath">/example</Set> <Set name="war"><Property name="jetty.webapps"/>/example.war</Set> <Set name="defaultsDescriptor">/path/to/fixed/webdefault.xml</Set> <Set name="overrideDescriptor">/path/to/override-web.xml</Set> </Configure>
Reminder, the load order for the effective web descriptor is …
- Default Descriptor – webdefault.xml
- WebApp Descriptor – WEB-INF/web.xml
- Override Descriptor – override.xml
If using the ResourceHandler (such as in an embedded-jetty setup), you’ll use the ResourceHandler.setDirAllowed(false) method.
Additionally, we discovered that usages of DefaultHandler were susceptible to a similar leak of information. If no webapp was mounted on the root “/” namespace, a page would be generated with links to other namespaces. This has been the default behavior in Jetty for years, but we have removed this to safeguard data.
As a result of these CVEs, we have released new versions for the 9.2.x, 9.3.x, and 9.4.x branches. The most up-to-date versions of all three are as follows, and are available both on the Jetty website and Maven Central.
Versions affected:- 9.2.27 and older (now EOL)
- 9.3.26 and older
- 9.4.16 and older
Resolved:
- 9.2.28.v20190418
- 9.3.27.v20190418
- 9.4.17.v20190418