Jetty 9 introduced the Eat-What-You-Kill[n]The EatWhatYouKill strategy is named after a hunting proverb in the sense that one should only kill to eat. The use of this phrase is not an endorsement of hunting nor killing of wildlife for food or sport.[/n] execution strategy to apply mechanically sympathetic techniques to the scheduling of threads in the producer-consumer pattern that are used for core capabilities in the server. The initial implementations proved vulnerable to thread starvation and Jetty-9.3 introduced dual scheduling strategies to keep the server running, which in turn suffered from lock contention on machines with more than 16 cores. The Jetty-9.4 release now contains the latest incarnation of the Eat-What-You-Kill scheduling strategy which provides mechanical sympathy without the risk of thread starvation in a single strategy. This blog is an update of the original post with the latest refinements.
Parallel Mechanical Sympathy
Parallel computing is a “false friend” for many web applications. The textbooks will tell you that parallelism is about decomposing large tasks into smaller ones that can be executed simultaneously by different computing engines to complete the task faster. While this is true, the issue is that for web application containers there is not an agreement on what is the “large task” that needs to be decomposed.
From the applications point of view the large task to be solved is how to render a complex page for a user, combining multiple requests and resources, using many services for authentication and perhaps RESTful access to a data model on multiple back end servers. For the application, parallelism can improve quality of service of rendering a single page by spreading the decomposed tasks over all the available CPUs of the server.
However, a web application container has a different large task to solve: how to provide service to hundreds or thousands, maybe even hundreds of thousands of simultaneous users. Unfortunately, for the container, the way to optimally allocate its this decomposed task to CPUs is completely opposite to how the application would like it’s decomposed tasks to be executed.
Consider a server with 4 CPUs serving 4 users each which each have 4 tasks. The applications ideal view of parallel decomposition looks like:
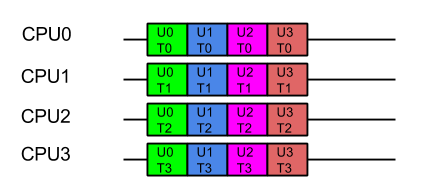
This view suggests that each user’s combined task will be executed in minimum time. However some users must wait for prior users tasks to complete before their execution can start, so average latency is higher.
Furthermore, we know from Mechanical Sympathy that such ideal execution is rarely possible, especially if there is data shared between tasks. Each CPU needs time to load its cache and register with data before it can be acted on. If that data is specific to the problem each user is trying to solve, then the real view of the parallel execution looks more like the following, the orange blocks indicating the time taken to load the CPU cache with user and task related data:
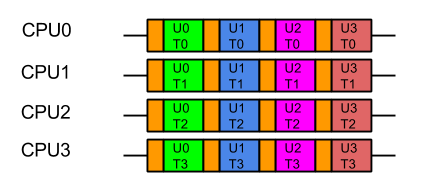
So from the containers point of view, the last thing it wants is the data from one users large problem spread over all its CPUs, because that means that when it executes the next task, it will have a cold cache and it must be reloaded with the data of the next user. Furthermore, executing tasks for the same user on different CPUs risks Parallel Slowdown, where the cost of mutual exclusion, synchronisation and communication between CPUs can increase the total time needed to execute the tasks to more than serial execution. If the tasks are fully mutually excluded on user data (unlikely but a bounding case), then the execution could look like:
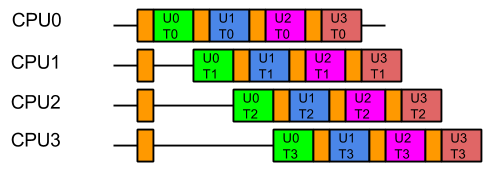
For optimal execution from the containers point of view it is far better if tasks from each user, which use common data, are kept on the same CPU so the cache only needs to be loaded once and there is no mutual exclusion on user data:
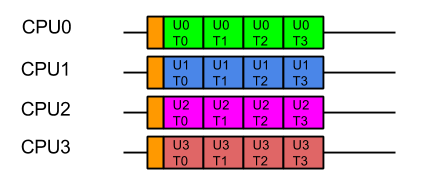
While this style of execution does not achieve the minimal latency and throughput of the idealised application view, in reality it is the fairest and most optimal execution, with all users receiving similar quality of service and the optimal average latency.
In summary, when scheduling the execution of parallel tasks, it is best to keep tasks that share data on the same CPU so that they may benefit from a hot cache (the original blog contains some micro benchmark results that quantifies the benefit).
Produce Consume (PC)
In order to facilitate the decomposition of large problems into smaller ones, the Jetty container uses the Producer-Consumer pattern:
- The NIO
Selectorproduces IO events that need to be consumed by reading, parsing and handling the data.
- A multiplexed HTTP/2 connection produces Frames that need to be consumed by calling the Servlet Container. Note that the producer of HTTP/2 frames is itself a consumer of IO events!
The producer-consumer pattern adds another way that tasks can be related by data. Not only might they be for the same user, but consuming a task will share the data that results from producing the task. A simple implementation can achieve this by using only a single CPU to both produce and consume the tasks:
while (true)
{
Runnable task = _producer.produce();
if (task == null)
break;
task.run();
}
The resulting execution pattern has good mechanical sympathy characteristics:

Here all the produced tasks are immediately consumed on the same CPU with a hot cache! Cache load times are minimised, but the cost is that server will suffer from Head of Line (HOL) Blocking, where the serial execution of task from a queue means that execution of tasks are forced to wait for the completion of unrelated tasks. In this case tasks for U1C0 need not wait for U0C0 and U2C0 tasks need not wait for U1C1 or U0C1 etc. There is no parallel execution and thus this is not an optimal usage of the server resources.
Produce Execute Consume (PEC)
To solve the HOL blocking problem, multiple CPUs must be used so that produced tasks can be executed in parallel and even if one is slow or blocks, the other CPU can progress the other tasks. To achieve this, a typical solution is to have one Thread executing on a CPU that will only produce tasks, which are then placed in a queue of tasks to be executed by Threads running on other CPUs. Typically the task queue is abstracted into an Executor:
while (true)
{
Runnable task = _producer.produce();
if (task == null)
break;
_executor.execute(task);
}
This strategy could be considered the canonical solution to the producer consumer problem, where producers are separated from consumers by a queue and is at the heart of architectures such as SEDA. This strategy well solves the head of line blocking issue, since all tasks produced can complete independently in different Threads on different CPUs:
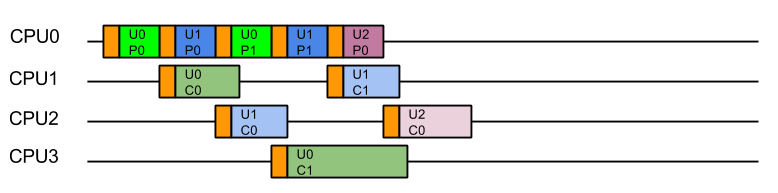
This represents a good improvement in throughput and average latency over the simple Produce Consume, solution, but the cost is that every consumed task is executed on a different Thread (and thus likely a different CPU) from the one that produced the task. While this may appear like a small cost for avoiding HOL blocking, our experience is that CPU cache misses significantly reduced the performance of early Jetty 9 releases.
Eat What You Kill (EWYK) AKA Execute Produce Consume (EPC)
To achieve good mechanical sympathy and avoid HOL blocking, Jetty has developed the Execute Produce Consume strategy, that we have nicknamed Eat What You Kill (EWYK) after the expression which states a hunter should only kill an animal they intend to eat. Applied to the producer consumer problem this policy says that a thread should only produce (kill) a task if it intends to consume (eat) it[n]The EatWhatYouKill strategy is named after a hunting proverb in the sense that one should only kill to eat. The use of this phrase is not an endorsement of hunting nor killing of wildlife for food or sport.[/n]. A task queue is still used to achieve parallel execution, but it is the producer that is dispatched rather than the produced task:
while (true)
{
Runnable task = _producer.produce();
if (task == null)
break;
_executor.execute(this); // dispatch production
task.run(); // consume the task ourselves
}
The result is that a task is consumed by the same Thread, and thus likely the same CPU, that produced it, so that consumption is always done with a hot cache:
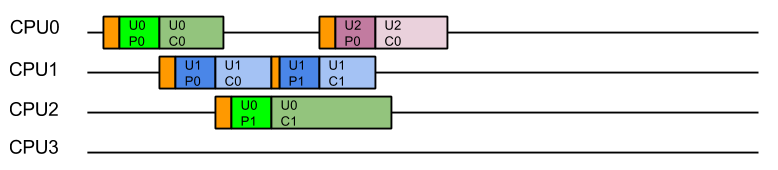
Moreover, because any thread that completes consuming a task will immediately attempt to produce another task, there is the possibility of a single Thread/CPU executing multiple produce/consume cycles for the same user. The result is improved average latency and reduced total CPU time.
Starvation!
Unfortunately, a pure implementation of EWYK suffers from a fatal flaw! Since any thread producing a task will go on to consume that task, it is possible for all threads/CPU to be consuming at once. This was initially seen as a feature as it exerted good back pressure on the network as a busy server used all its resources consuming existing tasks rather than producing new tasks. However, in an application server consuming a task may be a blocking process that waits for more data/frames to be produced. Unfortunately if every thread/CPU ends up consuming such a blocking task, then there are no threads left available to produce the tasks to unblock them. Dead lock!
A real example of this occurred with HTTP/2, when every Thread from the pool was blocked in a HTTP/2 request because it had used up its flow control window. The windows can be expanded by flow control frames from the other end, but there were no threads available to process the flow control frames!
Thus the EWYK execution strategy used in Jetty is now adaptive and it can can use the most appropriate of the three strategies outlined above, ensuring there is always at least one thread/CPU producing so that starvation does not occur. To be adaptive, Jetty uses two mechanisms:
- Tasks that are produced can be interrogated via the Invocable interface to determine if they are nonblocking, blocking or can be run in either mode. NON_BLOCKING or EITHER tasks can be directly consumed by PC model.
- The thread pools used by Jetty implement the TryExecutor interface which supports the method
boolean tryExecute(Runnable task)which allows the scheduler to know if a thread was available to continue producing and thus allows EWYK/EPC mode, otherwise the task must be passed to an executor to be consumed in PEC mode. To implement this semantic, Jetty maintains a dynamically sized pool of reserved threads that can respond totryExecute(Runnable)calls.
Thus the simple produce consume (PC) model is used for non-blocking tasks; for blocking tasks the EWYK, aka Execute Produce Consume (EPC) mode is used if a reserved thread is available, otherwise the SEDA style Produce Execute Consume (PEC) model is used.
The adaptive EWYK strategy can be written as :
while (true)
{
Runnable task = _producer.produce();
if (task == null)
break;
if (Invocable.getInvocationType(task)==NON_BLOCKING)
task.run(); // Produce Consume
else if (executor.tryExecute(this)) // recruit a new producer?
task.run(); // Execute Produce Consume (EWYK!)
else
executor.execute(task); // Produce Execute Consume
}
Chained Execution Strategies
As stated above, in the Jetty use-case it is common for the execution strategy used by the IO layer to call tasks that are themselves an execution strategy for producing and consuming HTTP/2 frames. Thus EWYK strategies can be chained and by knowing some information about the mode in which the prior strategy has executed them the strategies can be even more adaptive.
The adaptable chainable EWYK strategy is outlined here:
while (true) {
Runnable task = _producer.produce();
if (task == null)
break;
if (thisThreadIsNonBlocking())
{
switch(Invocable.getInvocationType(task))
{
case NON_BLOCKING:
task.run(); // Produce Consume
break;
case BLOCKING:
executor.execute(task); // Produce Execute Consume
break;
case EITHER:
executeAsNonBlocking(task); // Produce Consume break;
}
}
else
{
switch(Invocable.getInvocationType(task))
{
case NON_BLOCKING:
task.run(); // Produce Consume
break;
case BLOCKING:
if (_executor.tryExecute(this))
task.run(); // Execute Produce Consume (EWYK!)
else
executor.execute(task); // Produce Execute Consume
break;
case EITHER:
if (_executor.tryExecute(this))
task.run(); // Execute Produce Consume (EWYK!)
else
executeAsNonBlocking(task); // Produce Consume
break;
}
}
An example of how the chaining works is that the HTTP/2 task declares itself as invocable EITHER in blocking on non blocking mode. If IO strategy is operating in PEC mode, then the HTTP/2 task is in its own thread and free to block, so it can itself use EWYK and potentially execute a blocking task that it produced.
However, if the IO strategy has no reserved threads it cannot risk queuing an important Flow Control frame in a job queue. Instead it can execute the HTTP/2 as a non blocking task in the PC mode. So even if the last available thread was running the IO strategy, it can use PC mode to execute HTTP/2 tasks in non blocking mode. The HTTP/2 strategy is then always able to handle flow control frames as they are non-blocking tasks run as PC and all other frames that may block are queued with PEC.
Conclusion
The EWYK execution strategy has been implemented in Jetty to improve performance through mechanical sympathy, whilst avoiding the issues of Head of Line blocking, Thread Starvation and Parallel Slowdown. The team at Webtide continue to work with our clients and users to analyse and innovate better solutions to serve high performance real world applications.