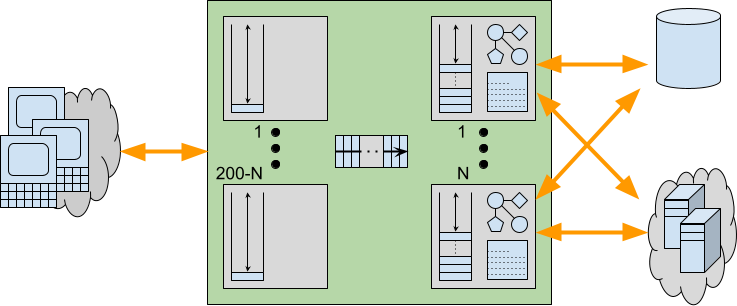
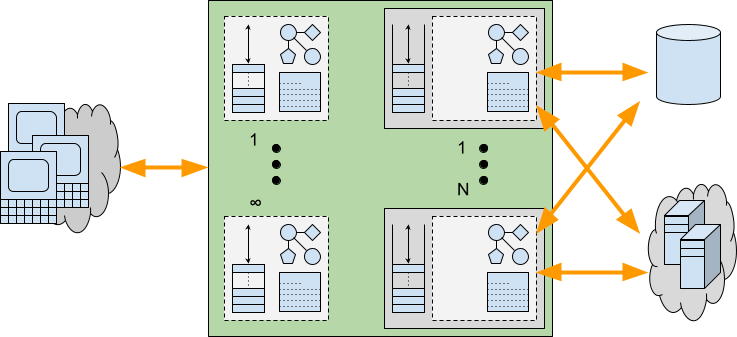
Webtide (https://webtide.com) is the company behind the open-source Jetty and CometD projects. Since 2006, Webtide has fully funded the Jetty and CometD projects through services and support, including migration assistance, production support, developer assistance, and CVE resolution.
First, the change.
Starting January 1, 2026, Webtide will no longer publish releases for Jetty 9, Jetty 10, and Jetty 11, as well as CometD 5, 6, and 7 to Maven Central or other public repositories.
Take a look at the primary announcement if you’re interested.
So, the motivation.
Why we are in this situation now harks back to the beginnings of Webtide. Briefly, Greg Wilkins founded the Jetty project in 1995 as part of a contest created by Sun Microsystems for a new language called Java. For a decade, he and Jan Bartel carefully stewarded the project as part of their consulting company Mort Bay Consulting. Around the Jetty 6 timeframe, in 2006, Webtide was founded as an LLC to evolve the project further commercially. Still, at its core, the goal was to support the incredible community that had developed over the years. When I joined in 2007, we began working to join the Eclipse Foundation. We took steps to formalize our development processes, aiming to add more commercial predictability to the open-source project. Joining the Eclipse Foundation also meant adhering to their rigorous IP policy for both the Jetty codebase and its dependencies, an essential step in improving corporate uptake.
This was also the time for the project to handle the end-of-life process for Jetty 6, while establishing Jetty 7 and Jetty 8. This was the opportunity that Webtide needed to support the project’s development by offering commercial services and support for EOL Jetty 6, while focusing on supporting and funding the future of Jetty 7 and Jetty 8.
It was the crux; after careful consideration, we decided that all commercial support releases would be open-source for the benefit of all. While not a traditional business decision, it aligned with our values and dedication to the community, which was rewarded as the community continued to grow its usage of Jetty.
This worked wonderfully for almost 20 years.
Something shifted…
We started to notice a shift in the community a few years ago. For almost 20 years, the companies we spoke with valued how our support could help them become more successful, with many ultimately becoming customers who truly understood the benefits of supporting open-source. Every single one of them saw the value in releasing EOL releases freely. When I became CEO a decade ago and Webtide became 100% developer-owned and operated, we were able to continue operating in this commercial environment with ease, to such an extent that the future of Webtide and the Jetty project is assured for many years to come.
So what changed? The tone of many companies we spoke to. Increasingly, while explaining the model that served Webtide well for so many years, where I used to hear ‘That makes so much sense, this works great!’, I now hear “So it’s just free? Great, I need to check a box.” Followed up with the galling question “Could you put this policy of yours in writing on your company letterhead?”.
And today?
Twenty years ago, things were different; Maven 2 dominance was emerging, and Maven Central was gaining ubiquity. Managing transitive dependencies was novel in many circles. Managing CVEs in a corporate setting was in its infancy, particularly with Java developer software stacks.
Now, build tooling is diverse, Maven Central is a global central repository system, and corporations should have their own caching repository servers, or they really should! Even JavaEE was rebranded as Jakarta at the Eclipse Foundation. So much change, but the one I’ll highlight is the emergence of business units focused on corporate software policies, complete with BOM files containing ever more metadata and checkboxes to click, managing CVE risks associated with software developed internally. Developers, the primary people Webtide has interacted with over the years, are increasingly far removed from software maintenance activities.
Now our approach to endlessly updating EOL releases seems remarkably outdated. Look at Jetty 9, which we have been releasing since 2013. It turns out our approach of making things as easy as possible for the community, for software that should have officially gone EOL years ago, was a benefit to many, but also enabled far more to grow complacent. Instead of scheduling migrations and updating to more recent versions, we inadvertently provided an environment that allowed companies to deploy onto software well over a decade old, when newer, more performant options were readily available. Then, when security postures started changing and businesses began looking deeper into their dependencies, they realized they were using outdated software, three or more major versions behind. Then, to our shock, many are perfectly fine with that so long as it is free and someone tells them it is ok.
If we have learned one thing within this time, it is that the EOL policy needs to be so much clearer, using established industry terminology. Looking back, we have been guilty of inventing terminology and inadvertently exacerbating the situation.
What is heartening is seeing other organizations work to address EOL as well; notably, MITRE has been developing changes to the CVE system to support EOL concepts fully. If you have ever seen the text “Unsupported When Assigned” in a CVE, then you have encountered the early efforts for EOL in a CVE.
You have to applaud the efforts of businesses to prioritize security and sane open-source policies.
However, this is also a call to open-source projects like Jetty, as we are operating in a different world. Everyone understands that ‘End-of-Life’ does not mean ‘End-of-Use’. Clearly, the system for many companies has changed from a Developer Support perspective to a Security Support perspective. EOL Software support is purchased differently now. There are companies, like Sonar (formerly Tidelift), that exist to manage security metadata about open-source software, enabling companies to manage their software risk more effectively.
EOL Jetty and CometD by Webtide
To address this industry evolution, Webtide has launched a partnership program that enables businesses relying on EOL Jetty and CometD versions to obtain CVE resolutions officially and predictably.
Webtide continues to resolve CVEs and issues for EOL Jetty and CometD in support of our commercial customers. However, the resulting binaries are now distributed directly to our commercial support customers and through our partnership network. No longer are we calling software EOL but deploying to Maven Central with a nod and a wink.
Our partners are established leaders in the open-source EOL landscape, creating products that directly address the problems the security and business industries are facing.
This synergy works perfectly with Webtide, as we are the company that offers services and support on Jetty and CometD. Migrations, developer assistance, production support, and performance are the things that directly influence the ongoing development of the open-source projects we steward. We can continue to focus on our strengths, and our partners can focus on theirs.
At last, the partners!
We are pleased to announce two partnerships. With these partners, you will be able to build a secure EOL solution for your software stack, not just for your usage of Jetty or CometD. Best yet, if you are interested in Webtide’s Lifecycle Support, you can use these partner versions in conjunction with our support!

TuxCare secures the open-source software the world builds on. Today, we protect over 1.2 million workloads – keeping them secure, compliant, and unstoppable at scale. From operating systems to development libraries and production applications, we power your open-source stack with enterprise-grade security and support, including endless lifecycle extensions for out-of-support software versions, rebootless patching for every major Linux distribution, enterprise-optimized support for community Linux, and our Linux-first vulnerability scanner that cuts through the noise.

HeroDevs provides secure, long-term maintenance for open-source frameworks that have reached End-of-Life. Through our Never-Ending Support (NES) initiative, we deliver continuous CVE remediation and compliance-grade updates, allowing your team to migrate at your own pace. Our engineers monitor upstream changes, backport verified fixes, and publish fully tested binaries for seamless drop-in replacement. With NES for Jetty and NES for CometD, you can stay secure, stable, and compliant—without refactoring or rushing a migration.
If your business is interested in our partner program, please direct inquiries to partnership@webtide.com.
Wrapping it up.
One important thing to note is that Webtide will continue to support the Jetty Project with a standard open-source release process, ensuring that older versions are released to provide the community with ample time to update to newer versions through a transition period. When Jetty 13 is released, Jetty 12.1 will continue to receive updates for a period, just as Jetty 12.0 does currently. If that is six months or a year, it remains to be seen. Once we finalize this release strategy with timelines, we will make sure the community is well-informed.
Fundamentally, the change coming is that the End of Life versions for Jetty and CometD will no longer be an empty EOL notice and quiet deployments to Maven Central. It will mean EOL and provide established industry solutions to address those who need additional support.